StrSwap
StrTran
StrZero
SubStr
CharAdd
CharAnd
CharEven
CharHist
CharList
CharMirr
CharMix
CharNoList
CharNot
CharOdd
CharOne
CharOnly
CharOr
CharPix
CharRela
CharRelRep
CharRem
CharRepl
CharRLL
CharRLR
CharSHL
CharSHR
CharSList
CharSort
CharSub
CharSwap
CharWin
CharXOR
CountLeft
CountRight
Descend
Empty
hb_At
hb_RAt
hb_ValToStr
IsAlpha
IsDigit
IsLower
IsUpper
NumAt
NumToken
PadLeft
PadRight
POSALPHA
POSCHAR
POSDEL
POSDIFF
POSEQUAL
POSINS
POSLOWER
POSRANGE
POSREPL
POSUPPER
TokenAt
TokenEnd
TokenExit
TokenInit
TokenLower
TokenNext
TokenNum
TokenSep
TokenUpper
Repeats a single character expression
Syntax
REPLICATE( <cString>, <nSize> ) --> cReplicateString
Arguments
<cString> Character string to be replicated
<nSize> Number of times to replicate <cString>
Returns
<cReplicateString> A character expression contain the <cString> fill character.
Description
This function returns a string composed of <nSize> repetitions of <cString>. The length of the character string returned by this function is limited to the memory available.
A value of 0 for <nSize> will return a NULL string.
Examples
? REPLICATE( "a", 10 ) // aaaaaaaaaa
? REPLICATE( "b", 100000 )
Tests
See Examples
Compliance
Clipper
Platforms
All (64K)
Files
Library is rtl
Seealso
SPACE(), PADC(), PADL(), PADR()
ADDSPACE()
Short:
------
ADDSPACE() Pads right of string with spaces
Returns:
--------
<cPaddedString> => String padded with spaces.
Syntax:
-------
ADDSPACE(cInString,nPadSpaces)
Description:
------------
Pads right side of <cInString> with <nPadSpaces> spaces.
Truncates string if <nPadSpaces> is shorter than
original string length.
Examples:
---------
ADDSPACE("GARRY",10) // => "GARRY "
Notes:
-------
For compatibility. In Clipper 5.x , the function
PADR() does the same thing.
Source:
-------
S_ADDSP.PRG
SPACE()
Return a string of spaces
------------------------------------------------------------------------------
Syntax
SPACE(<nCount>) --> cSpaces
Arguments
<nCount> is the number of spaces to be returned, up to a maximum of
65,535 (64 K).
Returns
SPACE() returns a character string. If <nCount> is zero, SPACE()
returns a null string ("").
Description
SPACE() is a character function that returns a specified number of
spaces. It is the same as REPLICATE("", <nCount>). SPACE() can
initialize a character variable before associating it with a GET.
SPACE() can also pad strings with leading or trailing spaces. Note,
however, that the PADC(), PADL(), and PADR() functions are more
effective for this purpose.
Examples
. This example uses SPACE() to initialize a variable for data
input:
USE Customer NEW
MEMVAR->Name = SPACE(LEN(Customer->Name))
@ 10,10 SAY "Customer Name" GET MEMVAR->Name
READ
Files Library is CLIPPER.LIB.
See Also: PAD() REPLICATE()
Section 2 – Faster Migration
Well …
Forget about all those mysterious DOS / console / command modes, batch processing, etc.
If you have tongs, don’t burn your hand!
Yes we have; so let’s use it:
Step : 1
Begin with making / assigning a folder for your works; FE : C:\MyWorks
Note : Working in a separate and clean folder is important.
Step : 2
Build a “Harbour Project” file : say MyTest01.hbp; and put a line into it :
My1stProg.prg
Step : 3
Build a a program file : say My1stProg.prg ; and write your very first program:
REQUEST HB_GT_WIN_DEFAULT
PROCEDURE Main
SETMODE( 25, 80 )
CLIENTE = SPACE( 15 )
@ 10, 15 SAY "Customer : " GET CLIENTE
READ
@ 12, 0
? CLIENTE
WAIT
RETURN
Step : 4
Open your .hbp file with HMG-IDE and press “Run” button.

That’s all !
Any other problem / question ?
Happy HMG’ing 😀
Definition:
In general, a Hash Table, or Hash Array, or Associative array, or shortly Hash is an array- like data structure, to store some data with an associated key for each; so, ‘atom’ of a hash is a pair of a ‘key’ with a ‘value’. A hash system needs to perform at least three operations:
– add a new pair,
– access to value via key
– the search and delete operations on a key pair
In Harbour, a hash is simply a special array, or more precisely a “keyed” array with special syntax with a set of functions.
Building:
The “=>” operator can be used to indicate literally the relation between <key> <value> pair: <key> => <value>
We can define and initialize a hash by this “literal” way :
hDigits_1 := { 1 => 1, 2 => 2, 3 => 3, 4 => 4 }
or by a special function call:
hDigits_1 := HB_HASH( 1, 1, 2, 2, 3, 3, 4, 4 )
Using “add” method may be another way :
hDigits_1 := { => } // Build an empty hash
hDigits_1[ 1] := 1
hDigits_1[ 2] := 2
hDigits_1[ 3] := 3
hDigits_1[ 4] := 4
In this method while evaluating each of above assignments, if given key exits in hash, will be replaced its value; else add a new pair to the hash.
In addition, data can be added to a hash by extended “+=” operator:
hCountries := { 'Argentina' => "Buenos Aires" }
hCountries += { 'Brasil' => "Brasilia" }
hCountries += { 'Chile' => "Santiago" }
hCountries += { 'Mexico' => "Mexico City" }
Hashs may add ( concatenate ) each other by extended “+” sign :
hFruits := { "fruits" => { "apple", "chery", "apricot" } }
hDays := { "days" => { "sunday", "monday" } }
hDoris := hFruits + hDays
Note: This “+” and “+=” operators depends xHB lib and needs to xHB lib and xHB.ch.
Typing :
<key> part of a hash may be any legal scalar type : C, D, L, N; and <value> part may be in addition scalar types, any complex type ( array or hash ).
Correction : This definition is wrong ! The correct is :
<key> entry key; can be of type: number, date, datetime, string, pointer.
Corrected at : 2015.12.08; thanks to Marek.
hDigits_2 := { 1 => “One”, 2 => “Two”, 3 => “Three”, 4 => “Four” }
hDigits_3 := { "1" => "One", "2" => "Two", "3" => "Three", "4" => "Four" }
hDigits_4 := { "1" => "One", 2 => "Two", 3 => "Three", "4" => "Four" }
hDigits_5 := { 1 => "One", 1 => "Two", 3 => "Three", 4 => "Four"
All of these examples are legal. As a result, a pair record of a hash may be:
– Numeric key, numeric value ( hDigits_1 )
– Numeric key, character value ( hDigits_2 )
– Character key, character value ( hDigits_3 )
– Mixed type key ( hDigits_4 )
Duplicate keys (as seen in hDigits_5) is permitted to assign, but not give a result such as double keyed values: LEN( hDigits_5 ) is 3, not 4; because first pair replaced by second due to has same key.
Consider a table-like data for customers records with two character fields: Customer ID and customer name:
| Cust_ID | Cust_Name |
| CC001 | Pierce Firth |
| CC002 | Stellan Taylor |
| CC003 | Chris Cherry |
| CC004 | Amanda Baranski |
We can build a hash with this data :
hCustomers := { "CC001" => "Pierce Firth",;
"CC002" => "Stellan Taylor",;
"CC003" => "Chris Cherry",;
"CC004" => "Amanda Baranski" }
and list it:
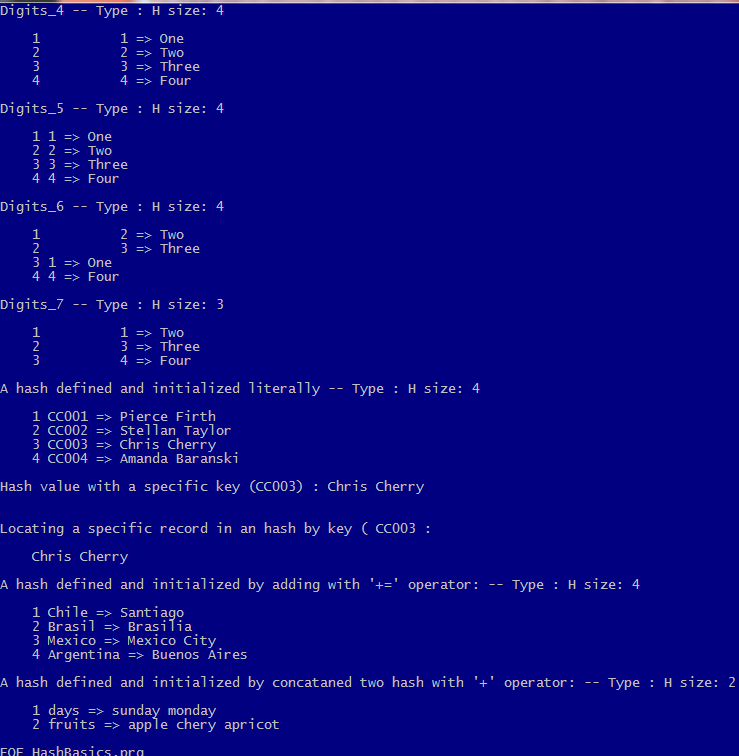
?
? "Listing a hash :"
?
h1Record := NIL
FOR EACH h1Record IN hCustomers
? cLMarj, h1Record:__ENUMKEY(), h1Record:__ENUMVALUE()
NEXT
Accessing a specific record is easy :
hCustomers[ "CC003" ] // Chris Cherry
*-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.
/*
Hash Basics
*/
#include "xhb.ch"
#define NTrim( n ) LTRIM( STR( n ) )
PROCEDURE Main()
SET DATE GERM
SET CENT ON
SET COLO TO "W/B"
cLMarj := SPACE( 3 )
CLS
hDigits_1 := { => } // Build an empty hash
hDigits_1[ 1 ] := 1
hDigits_1[ 2 ] := 2
hDigits_1[ 3 ] := 3
hDigits_1[ 4 ] := 4
ListHash( hDigits_1, "Digits_1" )
hDigits_2 := HB_HASH( 1, 1, 2, 2, 3, 3, 4, 4 )
ListHash( hDigits_2, "Digits_2" )
hDigits_3 := { 1 => 1,;
2 => 2,;
3 => 3,;
4 => 4 }
ListHash( hDigits_3, "Digits_3" )
hDigits_4 := { 1 => "One",;
2 => "Two",;
3 => "Three",;
4 => "Four" }
ListHash( hDigits_4, "Digits_4" )
hDigits_5 := { "1" => "One",;
"2" => "Two",;
"3" => "Three",;
"4" => "Four" }
ListHash( hDigits_5, "Digits_5" )
hDigits_6 := { "1" => "One",;
2 => "Two",;
3 => "Three",;
"4" => "Four" }
ListHash( hDigits_6, "Digits_6" )
hDigits_7 := { 1 => "One",;
1 => "Two",; // This line replace to previous due to same key
3 => "Three",;
4 => "Four" }
ListHash( hDigits_7, "Digits_7" )
* WAIT "EOF digits"
hCustomers := { "CC001" => "Pierce Firth",;
"CC002" => "Stellan Taylor",;
"CC003" => "Chris Cherry",;
"CC004" => "Amanda Baranski" }
ListHash( hCustomers, "A hash defined and initialized literally" )
?
? "Hash value with a specific key (CC003) :", hCustomers[ "CC003" ] // Chris Cherry
?
cKey := "CC003"
?
? "Locating a specific record in an hash by key (", cKey, ":"
?
c1Data := hCustomers[ cKey ]
? cLMarj, c1Data
hCountries := { 'Argentina' => "Buenos Aires" }
hCountries += { 'Brasil' => "Brasilia" }
hCountries += { 'Chile' => "Santiago" }
hCountries += { 'Mexico' => "Mexico City" }
ListHash( hCountries, "A hash defined and initialized by adding with '+=' operator:" )
hFruits := { "fruits" => { "apple", "chery", "apricot" } }
hDays := { "days" => { "sunday", "monday" } }
hDoris := hFruits + hDays
ListHash( hDoris, "A hash defined and initialized by concataned two hash with '+' operator:" )
?
@ MAXROW(), 0
WAIT "EOF HashBasics.prg"
RETURN // HashBasics.Main()
*-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.
PROCEDURE ListHash( hHash, cComment )
LOCAL x1Pair := NIL
cComment := IF( HB_ISNIL( cComment ), '', cComment )
?
? cComment, "-- Type :", VALTYPE( hHash ), "size:", NTrim ( LEN( hHash ) )
?
FOR EACH x1Pair IN hHash
nIndex := x1Pair:__ENUMINDEX()
x1Key := x1Pair:__ENUMKEY()
x1Value := x1Pair:__ENUMVALUE()
? cLMarj, NTrim( nIndex )
* ?? '', VALTYPE( x1Pair )
?? '', x1Key, "=>"
* ?? '', VALTYPE( x1Key )
* ?? VALTYPE( x1Value )
IF HB_ISARRAY( x1Value )
AEVAL( x1Value, { | x1 | QQOUT( '', x1 ) } )
ELSE
?? '', x1Value
ENDIF
NEXT
RETURN // ListHash()
*-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.

If a multi-dimension array
– have a fixed number elements in each dimension and
– each column contains the same type of information for each row in array
called “uniform”.
This structure is similar to a table structure.
Built-in functions DBSTRUCT() and DIRECTORY() produces uniform arrays.
Array produced by DBSTRUCT() will have field count in size and the structure of an array is:
Field Name C
Field Type C
Field Width N
Field Dec N
And DIRECTORY() function produces an array with elements as file count and with this structure:
File Name C
File Size N
File Date D
File Time C
File Attributes C
Building, maintaining and using those arrays is simple as possible.
Let’s look at a sample .prg:
-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._
#include "directry.ch"
#include "dbstruct.ch"
PROCEDURE Main()
SET DATE GERM
SET CENT ON
?
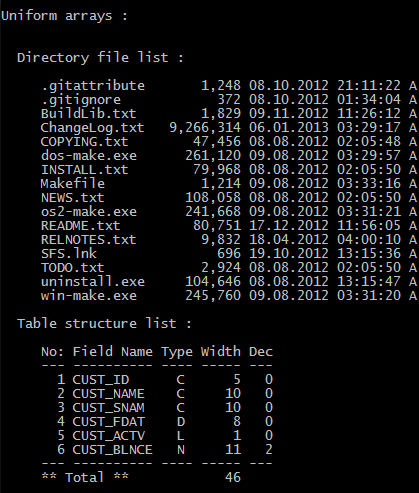
? "Uniform arrays :"
?
?
? " Directory file list :"
?
FileList()
?
? " Table structure list :"
?
IF MakUseTable()
DispStru()
ELSE
? "Couldn't USE or Make th table."
ENDIF
?
@ MAXROW(), 0
WAIT "EOF UF_Arrays.prg"
RETURN // UF_Arrays.Main
*-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._
PROCEDURE FileList()
LOCAL aFList := DIRECTORY( "C:\Harbour\*.*" )
LOCAL a1File
FOR EACH a1File IN aFList
? SPACE( 4 ),;
PAD( a1File[ F_NAME ], 13 ),; /* File name */
TRAN( a1File[ F_SIZE ], "999,999,999" ),; /* File size */
a1File[ F_DATE ],; /* File date */
a1File[ F_TIME ],; /* File time */
a1File[ F_ATTR ] /* File attribute */
NEXT
RETURN // FileList()
*-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._
FUNCTION MakUseTable()
LOCAL cTablName := "CUSTOMER.DBF"
LOCAL lRetval, aStru
IF FILE( cTablName )
USE (cTablName)
ELSE
aStru := { { "CUST_ID", "C", 5, 0 },;
{ "CUST_NAME", "C", 10, 0 },;
{ "CUST_SNAM", "C", 10, 0 },;
{ "CUST_FDAT", "D", 8, 0 },;
{ "CUST_ACTV", "L", 1, 0 },;
{ "CUST_BLNCE", "N", 11, 2 } }
*
* 5-th parameter of DBCREATE() is alias -
* if not given then WA is open without alias
* ^^^^^^^^^^^^^
DBCREATE( cTablName, aStru, , .F., "CUSTOMER" )
ENDIF
lRetval := ( ALIAS() == "CUSTOMER" )
RETURN lRetval // MakUseTable()
*-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._
PROCEDURE DispStru()
LOCAL nTotal := 1
IF SELECT() > 0
aStructur := DBSTRUCT()
? SPACE( 4 ), "No: Field Name Type Width Dec"
? SPACE( 4 ), "--- ---------- ---- ----- ---"
AEVAL( aStructur, { | aF1, nFNo | ;
QOUT( SPACE( 4 ),; // Left Marj
PADL( nFNo, 3 ),; // Field No
PADR( aF1[ DBS_NAME ], 11 ),; // Field Name
PADC( aF1[ DBS_TYPE ], 4 ),; // Field Type
PADL( aF1[ DBS_LEN ], 4 ),; // Field Len
PADL( aF1[ DBS_DEC ], 3 )),; // Field Dec
nTotal += aF1[ 3 ] } )
? SPACE( 4 ), "--- ---------- ---- ----- ---"
? SPACE( 4 ), "** Total ** ", TRAN( nTotal, "9,999" )
ELSE
? "Current work area is empty"
ENDIF
RETURN // DispStru()
*-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._
An array is a distinct data type which may contains multiple data items under same name. Data items stored in an array referred as an “element” and can be any data type. An individual element of array referenced by array name and position number of element as an integer in array, called “index” or “subscript”.
Defining / Building:
An array is a variable and like all variables has “scope”; arrays can be defined PRIVATE, PUBLIC and LOCAL as well as STATIC.
Building an array is quite simple: for example to define an array named “aColors” with 5 elements we can use a statement like this:
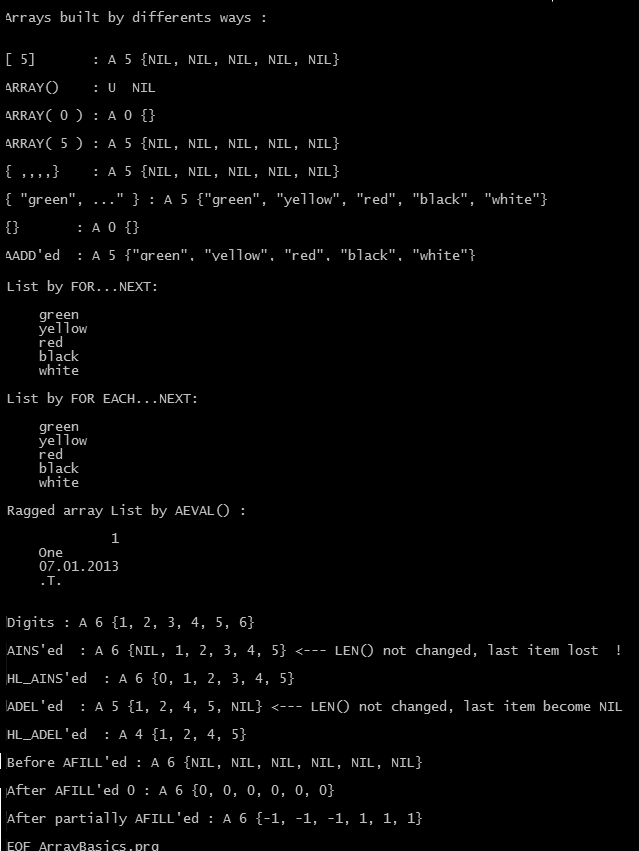
LOCAL aColors[ 5 ]
or
LOCAL aColors := ARRAY( 5 )
or
LOCAL aColors := { , , , , }
Results of these three methods are exactly same; we can inspect easily:
? ValType( aColors ) // A
? LEN( aColors ) // 5
? HB_ValToExp( aColors ) // {NIL, NIL, NIL, NIL, NIL}
NIL is a special data type with meaning “not defined”.
We can define an array with initial value(s)
aColors := { “green”, ”yellow” , “red”, “black”, “white” }
or assign values after defined:
aColors[ 1 ] := ”green”
aColors[ 2 ] := ”yellow”
aColors[ 3 ] := ”red”
aColors[ 4 ] := ”black”
aColors[ 5 ] := ”white”
? HB_ValToExp( aColors ) // {"green", "yellow", "red", "black", "white"}
Retrieve:
As seen in our first array statement
LOCAL aColors[ 5 ]
used a special sign square brackets as “Array element indicator” ( used also as string delimiter ).
As cited at the beginning, an individual element of array is referenced by array name and position number of element as an integer (enclosed by square brackets) in array, called “index” or “subscript”, and this notation called “subscripting”.
Note that subscribing begins with one.
To specify more than one subscript ( i.e. when using multi-dimensional arrays), you can either enclose each subscript in a separate set of square brackets, or separate the subscripts with commas and enclose the list in square brackets. For example, if aArray is a two dimensional array, the following statements both addresses the second column element of tenth row:
aArray[ 10 ][ 2] aArray[ 10, 2]
Of course it’s illegal to address an element that is outside of the boundaries of the array (lesser than one or greater than array size / length; one is also illegal for an empty array). Attempting to do so will result in a runtime error.
When making reference to an array element using a subscript, you are actually applying the subscript operator ([]) to an array expression, not only an array identifier (array variable name). An array expression is any valid expression that evaluate to an array. This includes function calls, variable references, subscripting operations, or any other expression that evaluate to an array. For example, the following are all valid:
{ “a”, “b”, “c” }[ 2 ]
x[ 2 ] ARRAY(3)[ 2 ] &(<macro expression>)[ 2 ] (<complex expression>)[ 2 ]
Syntax :
<aArrayName> [ <nSubscript> ]
<nSubscript> is integer value and indicate sequence number of element into this array.
With this way we can also traverse an array:
FOR nColor := 1 TO LEN( aColors ) ? aColors[ nColor ] NEXT nColor
In fact, with the other FOR loop, traversing an array doesn’t require subscripting:
cColor := “” // FOR EACH loop require a predefined loop element
FOR EACH cColor IN aColors ? cColor NEXT nColor
Elements of an array may be different data type; thus arrays called as “ragged” arrays in Clipper language.
aRagged := { 1, "One", DATE(), .T. }
FOR nIndex := 1 TO LEN( aRagged )
x1Elem := aRagged[ nIndex ]
? VALTYPE( x1Elem ), x1Elem
NEXT nIndex
A build-in array function AEVAL() can be use instead of a loop :
AEVAL( aRagged, { | x1 | QOUT(x1 ) } )
Adding one element to end of an array:
The architect of array is quite versatile. Array may change ( in size and element values ) dynamically at run time.
AADD() function can be used for add a new element to the end of an array
AADD(<aTarget>, <expValue>) --> Value
<aTarget> is the array to which a new element is to be added.
<expValue> is the value assigned to the new element.
AADD() is an array function that increases the actual length of the target array by one. The newly created array element is assigned the value specified by <expValue>.
AADD() is used to dynamically grow an array. It is useful for building dynamic lists or queues.
For example an array may build empty and later add element(s) to it :
aColors := {}
AADD( aColors, ”green” )
AADD( aColors, ”yellow” )
AADD( aColors, ”red” )
AADD( aColors, ”black” )
AADD( aColors, ”white” )
? HB_ValToExp( aColors ) // {"green", "yellow", "red", "black", "white"}
Inserting one element to an array:
AINS() function can be use for insert a NIL element into an array
AINS (<aTarget>, <nPosition>) --> aTarget
<aTarget> is the array into which a new element will be inserted.
<nPosition> is the position at which the new element will be inserted.
AINS() is an array function that inserts a new element into a specified array. The newly inserted element is NIL data type until a new value is assigned to it. After the insertion, the last element in the array is discarded, and all elements after the new element are shifted down one position.
For a lossless AINS() ( HL_AINS() ) look at attached .prg.
Deleting one element from an array:
ADEL(<aTarget>, <nPosition>) --> aTarget
ADEL() is an array function that deletes an element from an array. The content of the specified array element is lost, and all elements from that position to the end of the array are shifted up one element. The last element in the array becomes NIL. So, ADEL() function doesn’t change size of array.
For an another ADEL() ( HL_ADEL() ) look at attached .prg.
Resizing:
ASIZE() function can be use for grow or shrink, that is changing size of an array.
ASIZE( <aTarget>, <nLength>) --> aTarget
<aTarget> is the array to grow or shrink.
<nLength> is the new size of the array.
ASIZE() is an array function that changes the actual length of the <aTarget> array. The array is shortened or lengthened to match the specified length. If the array is shortened, elements at the end of the array are lost. If the array is lengthened, new elements are added to the end of the array and assigned NIL.
ASIZE() is similar to AADD() which adds a single new element to the end of an array and optionally assigns a new value at the same time. Note that ASIZE() is different from AINS() and ADEL(), which do not actually change the array’s length.
Assigning a fixed value to all elements of an array:
Changing values of all element of an array can not be accomplish by a simple assign statement. For example:
aTest := ARRAY( 3 ) aTest := 1
change type of aTest from array to numeric with a value 1.
Instead, AFILL() function gives a short way to fill an array with a fixed value.
AFILL() : Fill an array with a specified value
Syntax :
AFILL(<aTarget>, <expValue>,
[<nStart>], [<nCount>]) --> aTarget
<aTarget> is the array to be filled.
<expValue> is the value to be placed in each array element. It can be an expression of any valid data type.
<nStart> is the position of the first element to be filled. If this argument is omitted, the default value is one.
<nCount> is the number of elements to be filled starting with element <nStart>. If this argument is omitted, elements are filled from the starting element position to the end of the array.
Code evaluation on an array:
AEVAL()
Execute a code block for each element in an array
Syntax:
AEVAL(<aArray>, <bBlock>,
[<nStart>], [<nCount>]) --> aArray
Arguments:
<aArray> is the array to traverse.
<bBlock> is a code block to execute for each element encountered.
<nStart> is the starting element. If not specified, the default is element one.
<nCount> is the number of elements to process from <nStart>. If not specified, the default is all elements to the end of the array.
Returns:
AEVAL() returns a reference to <aArray>.
Description:
AEVAL() is an array function that evaluates a code block once for each element of an array, passing the element value and the element index as block parameters. The return value of the block is ignored. All elements in <aArray> are processed unless either the <nStart> or the <nCount> argument is specified.
AEVAL() makes no assumptions about the contents of the array elements it is passing to the block. It is assumed that the supplied block knows what type of data will be in each element.
AEVAL() is similar to DBEVAL() which applies a block to each record of a database file. Like DBEVAL(), AEVAL() can be used as a primitive for the construction of iteration commands for both simple and complex array structures.
Refer to the Code Blocks section in the “Basic Concepts” chapter of the Programming and Utilities Guide for more information on the theory and syntax of code blocks.
Examples :
This example uses AEVAL() to display an array of file names and file sizes returned from the DIRECTORY() function:
#include “Directry.ch”
//
LOCAL aFiles := DIRECTORY(“*.dbf”), nTotal := 0
AEVAL(aFiles, { | aDbfFile |;
QOUT( PADR(aDbfFile[F_NAME], 10), aDbfFile[F_SIZE]),;
nTotal += aDbfFile[F_SIZE])} )
//
?
? "Total Bytes:", nTotal
This example uses AEVAL() to build a list consisting of selected items from a multi-dimensional array:
#include "Directry.ch"
//
LOCAL aFiles := DIRECTORY("*.dbf"), aNames := {}
AEVAL(aFiles, { | file | AADD(aNames, file[F_NAME]) } )
This example changes the contents of the array element depending on a condition. Notice the use of the codeblock parameters:
LOCAL aArray[6]
AFILL(aArray,"old")
AEVAL(aArray,;
{|cValue,nIndex| IF( cValue == "old",;
aArray[nIndex] := "new",)})
Searching a value into an array :
ASCAN() : Scan an array for a value or until a block returns true (.T.)
Syntax:
ASCAN(<aTarget>, <expSearch>,
[<nStart>], [<nCount>]) --> nStoppedAt
Arguments:
<aTarget> is the array to be scanned.
<expSearch> is either a simple value to scan for, or a code block. If <expSearch> is a simple value it can be character, date, logical, or numeric type.
<nStart> is the starting element of the scan. If this argument is not specified, the default starting position is one.
<nCount> is the number of elements to scan from the starting position. If this argument is not specified, all elements from the starting element to the end of the array are scanned.
Returns:
ASCAN() returns a numeric value representing the array position of the last element scanned. If <expSearch> is a simple value, ASCAN() returns the position of the first matching element, or zero if a match is not found. If <expSearch> is a code block, ASCAN() returns the position of the element where the block returned true (.T.).
Description:
ASCAN() is an array function that scans an array for a specified value and operates like SEEK when searching for a simple value. The <expSearch> value is compared to the target array element beginning with the leftmost character in the target element and proceeding until there are no more characters left in <expSearch>. If there is no match, ASCAN() proceeds to the next element in the array.
Since ASCAN() uses the equal operator (=) for comparisons, it is sensitive to the status of EXACT. If EXACT is ON, the target array element must be exactly equal to the result of <expSearch> to match.
If the <expSearch> argument is a code block, ASCAN() scans the <aTarget> array executing the block for each element accessed. As each element is encountered, ASCAN() passes the element’s value as an argument to the code block, and then performs an EVAL() on the block. The scanning operation stops when the code block returns true (.T.), or ASCAN() reaches the last element in the array.
Examples:
This example demonstrates scanning a three-element array using simple values and a code block as search criteria. The code block criteria show how to perform a case-insensitive search:
aArray := { "Tom", "Mary", "Sue" }
? ASCAN(aArray, "Mary") // Result: 2
? ASCAN(aArray, "mary") // Result: 0
//
? ASCAN(aArray, { |x| UPPER(x) == "MARY" }) // Result: 2
This example demonstrates scanning for multiple instances of a search argument after a match is found:
LOCAL aArray := { "Tom", "Mary", "Sue","Mary" },;
nStart := 1
//
// Get last array element position
nAtEnd := LEN(aArray)
DO WHILE (nPos := ASCAN(aArray, "Mary", nStart)) > 0
? nPos, aArray[nPos]
//
// Get new starting position and test
// boundary condition
IF (nStart := ++nPos) > nAtEnd
EXIT
ENDIF
ENDDO
This example scans a two-dimensional array using a code block. Note that the parameter aVal in the code block is an array:
LOCAL aArr:={}
CLS
AADD(aArr,{"one","two"})
AADD(aArr,{"three","four"})
AADD(aArr,{"five","six"})
? ASCAN(aArr, {|aVal| aVal[2] == "four"}) // Returns 2
Sorting an array:
ASORT() : Sort an array
Syntax:
ASORT(<aTarget>, [<nStart>], [<nCount>], [<bOrder>]) --> aTarget
Arguments:
<aTarget> is the array to be sorted.
<nStart> is the first element of the sort. If not specified, the default starting position is one.
<nCount> is the number of elements to be sorted. If not specified, all elements in the array beginning with the starting element are sorted.
<bOrder> is an optional code block used to determine sorting order. If not specified, the default order is ascending.
Returns:
ASORT() returns a reference to the <aTarget> array.
Description:
ASORT() is an array function that sorts all or part of an array containing elements of a single data type. Data types that can be sorted include character, date, logical, and numeric.
If the <bOrder> argument is not specified, the default order is ascending. Elements with low values are sorted toward the top of the array (first element), while elements with high values are sorted toward the bottom of the array (last element).
If the <bOrder> block argument is specified, it is used to determine the sorting order. Each time the block is evaluated; two elements from the target array are passed as block parameters. The block must return true (.T.) if the elements are in sorted order. This facility can be used to create a descending or dictionary order sort. See the examples below.
When sorted, character strings are ordered in ASCII sequence; logical values are sorted with false (.F.) as the low value; date values are sorted chronologically; and numeric values are sorted by magnitude.
Notes:
ASORT() is only guaranteed to produce sorted output (as defined by the block), not to preserve any existing natural order in the process.
Because multidimensional arrays are implemented by nesting sub-arrays within other arrays, ASORT() will not directly sort a multidimensional array. To sort a nested array, you must supply a code block which properly handles the sub-arrays.
Examples:
This example creates an array of five unsorted elements, sorts the array in ascending order, then sorts the array in descending order using a code block:
aArray := { 3, 5, 1, 2, 4 }
ASORT(aArray)
// Result: { 1, 2, 3, 4, 5 }
ASORT(aArray,,, { |x, y| x > y })
// Result: { 5, 4, 3, 2, 1 }
This example sorts an array of character strings in ascending order, independent of case. It does this by using a code block that converts the elements to uppercase before they are compared:
aArray := { "Fred", Kate", "ALVIN", "friend" }
ASORT(aArray,,, { |x, y| UPPER(x) < UPPER(y) })
This example sorts a nested array using the second element of each sub-array:
aKids := { {"Mary", 14}, {"Joe", 23}, {"Art", 16} }
aSortKids := ASORT(aKids,,, { |x, y| x[2] < y[2] })
Result:
{ {“Mary”, 14}, {“Art”, 16}, {“Joe”, 23} }
Last element in an array:
ATAIL() : Return the highest numbered element of an array
Syntax:
ATAIL(<aArray>) --> Element
Arguments:
<aArray> is the array.
Returns:
ATAIL() returns either a value or a reference to an array or object. The array is not changed.
Description:
ATAIL() is an array function that returns the highest numbered element of an array. It can be used in applications as shorthand for <aArray>[LEN(<aArray>)] when you need to obtain the last element of an array.
Examples:
The following example creates a literal array and returns that last element of the array:
aArray := {"a", "b", "c", "d"}
? ATAIL(aArray) // Result: d
Getting directory info:
ADIR() is a array function to obtain directory information. But it’s a compatibility function and therefore not recommended. It is superseded by the DIRECTORY() function which returns all file information in a multidimensional array.
A sample .prg : ArrayBasics.prg
Add a new element to the end of an array
AADD( <aTarget>, <expValue> ) --> Value
Duplicate a nested or multidimensional array
ACLONE( <aSource> ) --> aDuplicate
Copy elements from one array to another
ACOPY( <aSource>, <aTarget>, [ <nStart> ], [ <nCount> ],
[ <nTargetPos> ] ) --> aTarget
Delete an array element
ADEL( <aTarget>, <nPosition> ) --> aTarget
Fill a series of arrays with directory information
ADIR([ <cFilespec> ],
[ <aFilenames> ],
[ <aSizes> ],
[ <aDates> ],
[ <aTimes> ],
[ <aAttributes> ] ) --> nFiles
Execute a code block for each element in an array
AEVAL( <aArray>, <bBlock>, [ <nStart> ], [ <nCount> ] ) --> aArray
Fill an array with a specified value
AFILL( <aTarget>, <expValue>, [ <nStart> ], [ <nCount> ] )
--> aTarget
Insert a NIL element into an array
AINS( <aTarget>, <nPosition> ) --> aTarget
Create an uninitialized array of specified length
ARRAY( <nElements> [, <nElements>...] ) --> aArray
Scan an array for a value or until a block returns (.T.)
ASCAN( <aTarget>, <expSearch>, [ <nStart> ], [ <nCount> ] )
--> nStoppedAt
Grow or shrink an array
ASIZE( <aTarget>, <nLength> ) --> aTarget
Sort an array
ASORT( <aTarget>, [ <nStart> ], [ <nCount> ], [ <bOrder> ] )
--> aTarget
Return value of the highest numbered (last) element of an array
ATAIL( <aArray> ) --> Element
Determine if the result of an expression is empty
EMPTY( <exp> ) --> lEmpty
Return the length of a character string or array size
LEN( <cString> | <aArray> ) --> nCount
Return the larger of two numeric or date values
MAX( <nExp1>, <nExp2> ) --> nLarger MAX( <dExp1>, <dExp2> ) --> dLarger
Return the smaller of two numeric or date values
MIN( <nExp1>, <nExp2> ) --> nSmaller MIN( <dExp1>, <dExp2> ) --> dSmaller
Pad character, date or numeric values with a fill character
PADL( <exp>, <nLength>, [ <cFillChar> ] ) --> cPaddedString PADC( <exp>, <nLength>, [ <cFillChar> ] ) --> cPaddedString PADR( <exp>, <nLength>, [ <cFillChar> ] ) --> cPaddedString
Convert any value into a formatted character string
TRANSFORM( <exp>, <cSayPicture> ) --> cFormatString
Determine the type of an expression
TYPE( <cExp> ) --> cType
Determine the data type returned by an expression
VALTYPE( <exp> ) --> cType
Convert a date value to a character day of the week
CDOW( <dExp> ) --> cDayName
Convert a date to a character month name
CMONTH( <dDate> ) --> cMonth
Convert a date string to a date value
CTOD( <cDate> ) --> dDate
Return the system date as a date value
DATE() --> dSystem
Return the day of the month as a numeric value
DAY( <dDate> ) --> nDay
Convert a date value to a numeric day of the week
DOW( <dDate> ) --> nDay
Convert a date value to a character string
DTOC( <dDate> ) --> cDate
Convert a date value to a string formatted as yyyymmdd
DTOS( <dDate> ) --> cDate
Convert a date value to the number of the month
MONTH( <dDate> ) --> nMonth
Return the number of seconds elapsed since midnight
SECONDS() --> nSeconds
Return the system time
TIME() --> cTimeString
Convert a date value to the year as a numeric value
YEAR( <dDate> ) --> nYear
Return the absolute value of a numeric expression
ABS( <nExp> ) --> nPositive
Convert a 16-bit signed integer to a numeric value
BIN2I( <cSignedInt> ) --> nNumber
Convert a 32-bit signed integer to a numeric value
BIN2L( <cSignedInt> ) --> nNumber
Convert a 16-bit unsigned integer to a numeric value
BIN2W( <cUnsignedInt> ) --> nNumber
Calculate e**x
EXP( <nExponent> ) --> nAntilogarithm
Convert a numeric value to an integer
INT( <nExp> ) --> nInteger
Convert a numeric to a 16-bit binary integer
I2BIN( <nInteger> ) --> cBinaryInteger
Calculate the natural logarithm of a numeric value
LOG( <nExp> ) --> nNaturalLog
Convert a numeric value to a 32-bit binary integer
L2BIN( <nExp> ) --> cBinaryInteger
Return dBASE III PLUS modulus of two numbers
MOD( <nDividend>, <nDivisor> ) --> nRemainder
Return a value rounded to a specified number of digits
ROUND( <nNumber>, <nDecimals> ) --> nRounded
Return the square root of a positive number
SQRT( <nNumber> ) --> nRoot
Convert a character number to numeric type
VAL( <cNumber> ) --> nNumber
Remove leading and trailing spaces from character string
ALLTRIM( <cString> ) --> cTrimString
Convert a character to its ASCII value
ASC( <cExp> ) --> nCode
Return the position of a substring within a string
AT( <cSearch>, <cTarget> ) --> nPosition
Convert an ASCII code to a character value
CHR( <nCode> ) --> cChar
Replace all soft CRs with hard CRs
HARDCR( <cString> ) --> cConvertedString
Determine if the leftmost character is alphabetic
ISALPHA( <cString> ) --> lBoolean
Determine if the leftmost character is a digit
ISDIGIT( <cString> ) --> lBoolean
Determine if the leftmost character is a lower case letter
ISLOWER( <cString> ) --> lBoolean
Determine if the leftmost character is upper case
ISUPPER( <cString> ) --> lBoolean
Extract a substring beginning with the first character
LEFT( <cString>, <nCount> ) --> cSubString
Convert uppercase characters to lowercase
LOWER( <cString> ) --> cLowerString
Remove leading spaces from a character string
LTRIM( <cString> ) --> cTrimString
Display or edit character strings and memo fields
MEMOEDIT( [ <cString> ],
[ <nTop> ], [ <nLeft> ],
[ <nBottom> ], [ <nRight> ],
[ <lEditMode> ],
[ <cUserFunction> ],
[ <nLineLength> ],
[ <nTabSize> ],
[ <nTextBufferRow> ],
[ <nTextBufferColumn> ],
[ <nWindowRow> ],
[ <nWindowColumn> ] ) --> cTextBuffer
Extract a line of text from character string or memo field
MEMOLINE( <cString>,
[ <nLineLength> ],
[ <nLineNumber> ],
[ <nTabSize> ],
[ <lWrap> ] ) --> cLine
Return the contents of a disk file as a character string
MEMOREAD( <cFile> ) --> cString
Replace carriage return/line feeds in character strings
MEMOTRAN( <cString>,
[ <cReplaceHardCR> ],
[ <cReplaceSoftCR> ] ) --> cNewString
Write a character string or memo field to a disk file
MEMOWRIT( <cFile>, <cString> ) --> lSuccess
Count the lines in a character string or memo field
MLCOUNT( <cString>, [ <nLineLength> ], [ <nTabSize> ],
[ <lWrap> ] ) --> nLines
Return byte position based on line and column position
MLCTOPOS( <cText>, <nWidth>, <nLine>,
<nCol>, [ <nTabSize> ], [ <lWrap> ] ) --> nPosition
Determine the position of a line in a memo field
MLPOS( <cString>, <nLineLength>,
<nLine>, [ <nTabSize> ], [ <lWrap> ] ) --> nPosition
Return line and column position based on byte position
MPOSTOLC( <cText>, <nWidth>, <nPos>,
[ <nTabSize> ], [ <lWrap> ] ) --> aLineColumn
Return the position of the last occurrence of a substring
RAT( <cSearch>, <cTarget> ) --> nPosition
Return a string repeated a specified number of times
REPLICATE( <cString>, <nCount> ) --> cRepeatedString
Return a substring beginning with rightmost character
RIGHT( <cString>, <nCount> ) --> cSubString
Remove trailing spaces from a character string
RTRIM( <cString> ) --> cTrimString
Toggle exact matches for character strings
SET EXACT on | OFF | <xlToggle>
Convert a character string to soundex form
SOUNDEX( <cString> ) --> cSoundexString
Return a string of spaces
SPACE( <nCount> ) --> cSpaces
Convert a numeric expression to a character string
STR( <nNumber>, [ <nLength> ], [ <nDecimals> ] ) --> cNumber
Search and replace characters within a character string
STRTRAN( <cString>, <cSearch>, [ <cReplace> ],
[ <nStart> ], [ <nCount> ] ) --> cNewString
Delete and insert characters in a string
STUFF( <cString>, <nStart>, <nDelete>, <cInsert> ) --> cNewString
Extract a substring from a character string
SUBSTR( <cString>, <nStart>, [ <nCount> ] ) --> cSubstring
Remove trailing spaces from a character string
TRIM( <cString> ) --> cTrimString
Convert lowercase characters to uppercase
UPPER( <cString> ) --> cUpperString