Tag Archives: LTRIM()
String Functions
CharAdd
CharAnd
CharEven
CharHist
CharList
CharMirr
CharMix
CharNoList
CharNot
CharOdd
CharOne
CharOnly
CharOr
CharPix
CharRela
CharRelRep
CharRem
CharRepl
CharRLL
CharRLR
CharSHL
CharSHR
CharSList
CharSort
CharSub
CharSwap
CharWin
CharXOR
CountLeft
CountRight
Descend
Empty
hb_At
hb_RAt
hb_ValToStr
IsAlpha
IsDigit
IsLower
IsUpper
NumAt
NumToken
PadLeft
PadRight
POSALPHA
POSCHAR
POSDEL
POSDIFF
POSEQUAL
POSINS
POSLOWER
POSRANGE
POSREPL
POSUPPER
TokenAt
TokenEnd
TokenExit
TokenInit
TokenLower
TokenNext
TokenNum
TokenSep
TokenUpper
Trim()
Trim()
Remove trailing spaces from a string.
Syntax
Trim( <cExpression> ) --> cString
Arguments
<cExpression> Any character expression
Returns
<cString> A formatted string with out any blank spaced.
Description
This function returns the value of <cString> with any trailing blank removed.
This function is identical to RTrim() and the opposite of LTrim(). Together with LTrim(), this function equated to the AllTrim() function.
Note : Characters with ASCII code 9, 10 and 13 always treated as “white spaces”.
Examples
? Trim( "HELLO" ) // "HELLO"
? Trim( "" ) // ""
? Trim( "UA " ) // "UA"
? Trim( " UA" ) // " UA"
Compliance
Clipper
Platforms
All
Files
Library is core
Seealso
RTrim(), LTrim(), AllTrim()
RTrim()
RTRIM()
Remove trailing spaces from a string.
Syntax
RTRIM( <cExpression> ) --> cString
Arguments
<cExpression> Any character expression
Returns
<cString> A formatted string with out any blank spaced.
Description
This function returns the value of <cString> with any trailing blank removed.
This function is identical to RTRIM() and the opposite of LTRIM(). Together with LTRIM(), this function equated to the ALLTRIM() function.
Note : Characters with ASCII code 9, 10 and 13 always treated as “white spaces”.
Examples
? RTRIM( "HELLO" ) // "HELLO"
? RTRIM( "" ) // ""
? RTRIM( "UA " ) // "UA"
? RTRIM( " UA" ) // " UA"
Tests
See Examples
Compliance
Clipper
Platforms
All
Files
Library is rtl
Seealso
ALLTRIM(), LTRIM(), TRIM()
Len()
LEN()
Returns size of a string or size of an array.
Syntax
LEN( <cString> | <aArray> ) --> <nLength>
Arguments
<acString> is a character string or the array to check.
Returns
The length of the string or the number of elements that contains an array.
Description
This function returns the string length or the size of an array or the size of a hash table. If it is used with a multidimensional array it returns the size of the first dimension.
Examples
? LEN( "Harbour" ) // 7
? LEN( { "One", "Two" } ) // 2
Tests
PROCEDURE Test()
LOCAL cName := ""
ACCEPT "Enter your name: " TO cName
? LEN( cName )
RETURN
Compliance
Clipper
Files
Library is rtl
Seealso
EMPTY(), RTRIM(), LTRIM(), AADD(), ASIZE()
AllTrim()
ALLTRIM()
Removes leading and trailing blank spaces from a string
Syntax
ALLTRIM( <cString> ) --> cExpression
Arguments
<cString> Any character string
Returns
<cExpression> An string will all blank spaces removed from <cString>
Description
This function returns the string <cExpression> will all leading and trailing blank spaces removed.
Note : Characters with ASCII code 9, 10 and 13 always treated as “white spaces”.
Examples
? ALLTRIM( "HELLO HARBOUR" )
? ALLTRIM( " HELLO HARBOUR" )
? ALLTRIM( "HELLO HARBOUR " )
? ALLTRIM( " HELLO HARBOUR " )
Compliance
Clipper
Platforms
All
Files
Library is rtl
Seealso
LTRIM(), RTRIM(), TRIM()
SP_LJUST
LJUST() Short: ------ LJUST() Left justifies a string Returns: -------- <cJustified> => string left justified Syntax: ------- LJUST(cTarget) Description: ------------ Left justifies <cTarget> Examples: --------- string = " Superfunction" string = LJUST(string) // (returns "Superfunction " Source: ------- S_LJUST.PRG
C5_LTRIM
LTRIM()
Remove leading spaces from a character string
------------------------------------------------------------------------------
Syntax
LTRIM(<cString>) --> cTrimString
Arguments
<cString> is the character string to copy without leading spaces.
Returns
LTRIM() returns a copy of <cString> with the leading spaces removed. If
<cString> is a null string ("") or all spaces, LTRIM() returns a null
string ("").
Description
LTRIM() is a character function that formats character strings with
leading spaces. These can be, for example, numbers converted to
character strings using STR().
LTRIM() is related to RTRIM(), which removes trailing spaces, and
ALLTRIM(), which removes both leading and trailing spaces. The inverse
of ALLTRIM(), LTRIM(), and RTRIM() are the PADC(), PADR(), and PADL()
functions which center, right-justify, or left-justify character strings
by padding them with fill characters.
Notes
. Space characters: The LTRIM() function treats carriage
returns, line feeds, and tabs as space characters and removes these
as well.
Examples
. These examples illustrate LTRIM() used with several other
functions:
nNumber = 18
? STR(nNumber) // Result: 18
? LEN(STR(nNumber)) // Result: 10
? LTRIM(STR(nNumber)) // Result: 18
? LEN(LTRIM(STR(nNumber))) // Result: 2
Files Library is CLIPPER.LIB.
See Also: ALLTRIM() PAD() RTRIM() STR() SUBSTR() TRIM()
Hash Details – 1
Some details of hash manipulations:
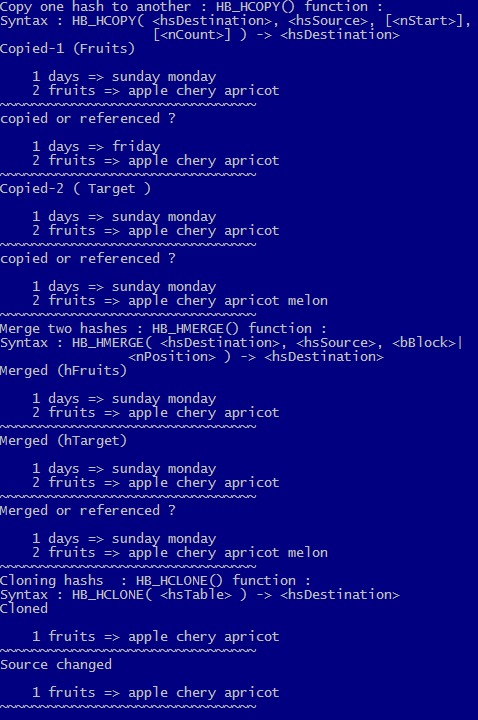
HB_HCOPY() function copies a hash to another.
Syntax :
HB_HCOPY( <hsDestination>, <hsSource>, [<nStart>], [<nCount>] ) ->
<hsDestination>
As noticed in syntax, copy operation may be limited by [<nStart>], [<nCount>] arguments.
But a hash may NOT built by “COPY” method; because <hsDestination> argument isn’t optional.
hFruits := { "fruits" => { "apple", "cherry", "apricot" } }
hFruits2 := HB_HCOPY( hFruits ) // Argument error !
Though it’s possible in two steps:
hFruits2 := HB_HASH() // Built first an empty hash
hFruits2 := HB_HCOPY(hFruits2, hFruits ) // copy second onto first
As a result, for hash copy process two hashes should be exist:
hFruits := { "fruits" => { "apple", "cherry", "apricot" } }
hDays := { "days" => { "sunday", "monday" } }
hFruits := HB_HCOPY( hFruits, hDays )
or
hFruits := { "fruits" => { "apple", "cherry", "apricot" } }
hDays := { "days" => { "sunday", "monday" } }
hTarget := HB_HASH()
hTarget := HB_HCOPY( hTarget, hFruits )
hTarget := HB_HCOPY( hTarget, hDays )
HB_HMERGE() function merge two hashes.
Syntax:
HB_HMERGE( <hsDestination>, <hsSource>, <bBlock>|<nPosition> ) ->
<hsDestination>
hFruits := { "fruits" => { "apple", "cherry", "apricot" } }
hDays := { "days" => { "sunday", "monday" } }
hMerged := HB_HMERGE( hFruits, hDays )
hFruits :
1 days => sunday monday
2 fruits => apple cherry apricot
hTarget :
1 days => sunday monday
2 fruits => apple cherry apricot
AADD( hFruits[ "fruits" ], "melon" )
hFruits and hTarget :
1 days => sunday monday
2 fruits => apple cherry apricot melon
Result of above tests :
HB_HCOPY() and HB_HMERGE() doesn’t “physically” copy / merge hashes data; instead, copy / merge only by reference(s).
HB_HCLONE() function : Cloning (exact copy of) hashes.
Syntax:
HB_HCLONE( <hsTable> ) -> <hsDestination>
hFruits := { "fruits" => { "apple", "cherry", "apricot" } }
hClone := HB_HCLONE( hFruits )
hClone : fruits => apple cherry apricot
AADD( hFruits[ "fruits" ], "melon" ) // Source changed
hClone : fruits => apple cherry apricot
*-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._./*
Hash Details - 1
Copy, Merge & Clone Hashes.
*/
#define NTrim( x ) IF( HB_ISNUMERIC( x ), LTRIM( STR( x ) ), x )
PROCEDURE Main()
SET COLO TO "W/B"
cLMarj := SPACE( 3 )
CLS
? "Copy one hash to another : HB_HCOPY() function : "
? "Syntax :",;
"HB_HCOPY( <hsDestination>, <hsSource>, [<nStart>],"
? " [<nCount>] ) -> <hsDestination>"
hFruits := { "fruits" => { "apple", "cherry", "apricot" } }
hDays := { "days" => { "sunday", "monday" } }
* hFruits2 := HB_HCOPY( hFruits ) // Argument error !
hFruits := HB_HCOPY( hFruits, hDays )
ListHash( hFruits, "Copied-1 (Fruits)" )
hDays[ "days" ] := "friday"
ListHash( hFruits, "copied or referenced ?" )
hTarget := HB_HASH()
hFruits := { "fruits" => { "apple", "cherry", "apricot" } }
hDays := { "days" => { "sunday", "monday" } }
hTarget := HB_HCOPY( hTarget, hFruits )
hTarget := HB_HCOPY( hTarget, hDays )
ListHash( hTarget, "Copied-2 ( Target )" )
AADD( hFruits[ "fruits" ], "melon" )
ListHash( hTarget, "copied or referenced ?" )
? "Merge two hashes : HB_HMERGE() function : "
? "Syntax :",;
"HB_HMERGE( <hsDestination>, <hsSource>, <bBlock>|"
? " <nPosition> ) -> <hsDestination>"
hFruits := { "fruits" => { "apple", "cherry", "apricot" } }
hDays := { "days" => { "sunday", "monday" } }
hMerged := HB_HMERGE( hFruits, hDays )
ListHash( hFruits, "Merged (hFruits)" )
ListHash( hMerged, "Merged (hTarget)" )
AADD( hFruits[ "fruits" ], "melon" )
ListHash( hFruits, "Merged or referenced ? ( hFruits) " )
ListHash( hMerged, "Merged or referenced ? ( hMerged) " )
*
* Result of above tests :
*
* HB_HCOPY() and HB_HMERGE() doesn't "physically" copy / merge hashes data;
*
* instead copy / merge only by reference(s).
*
? "Cloning (exact copy of) hashes : HB_HCLONE() function : "
? "Syntax :",;
"HB_HCLONE( <hsTable> ) -> <hsDestination>"
hFruits := { "fruits" => { "apple", "cherry", "apricot" } }
hClone := HB_HCLONE( hFruits )
ListHash( hClone, "Cloned" )
AADD( hFruits[ "fruits" ], "melon" )
ListHash( hClone, "Source changed" )
?
@ MAXROW(), 0
WAIT "EOF HashDetails-1.prg"
RETURN // HashDetails-1.Main()
*-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.
PROCEDURE ListHash( hHash, cComment )
LOCAL x1Pair := NIL
cComment := IF( HB_ISNIL( cComment ), '', cComment )
? cComment, ''
* ?? "-- Type :", VALTYPE( hHash ),''
* ?? "size:", NTrim ( LEN( hHash ) )
?
FOR EACH x1Pair IN hHash
nIndex := x1Pair:__ENUMINDEX()
x1Key := x1Pair:__ENUMKEY()
x1Value := x1Pair:__ENUMVALUE()
? cLMarj, NTrim( nIndex )
* ?? '', VALTYPE( x1Pair )
?? '', NTrim( x1Key ), "=>"
* ?? '', VALTYPE( x1Key )
* ?? VALTYPE( x1Value )
IF HB_ISARRAY( x1Value )
AEVAL( x1Value, { | x1 | QQOUT( '', x1 ) } )
ELSE
?? '', NTrim( x1Value )
ENDIF
NEXT
? REPL( "~", 32 )
RETURN // ListHash()
*-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.

Hash Basics
Definition:
In general, a Hash Table, or Hash Array, or Associative array, or shortly Hash is an array- like data structure, to store some data with an associated key for each; so, ‘atom’ of a hash is a pair of a ‘key’ with a ‘value’. A hash system needs to perform at least three operations:
– add a new pair,
– access to value via key
– the search and delete operations on a key pair
In Harbour, a hash is simply a special array, or more precisely a “keyed” array with special syntax with a set of functions.
Building:
The “=>” operator can be used to indicate literally the relation between <key> <value> pair: <key> => <value>
We can define and initialize a hash by this “literal” way :
hDigits_1 := { 1 => 1, 2 => 2, 3 => 3, 4 => 4 }
or by a special function call:
hDigits_1 := HB_HASH( 1, 1, 2, 2, 3, 3, 4, 4 )
Using “add” method may be another way :
hDigits_1 := { => } // Build an empty hash
hDigits_1[ 1] := 1
hDigits_1[ 2] := 2
hDigits_1[ 3] := 3
hDigits_1[ 4] := 4
In this method while evaluating each of above assignments, if given key exits in hash, will be replaced its value; else add a new pair to the hash.
In addition, data can be added to a hash by extended “+=” operator:
hCountries := { 'Argentina' => "Buenos Aires" }
hCountries += { 'Brasil' => "Brasilia" }
hCountries += { 'Chile' => "Santiago" }
hCountries += { 'Mexico' => "Mexico City" }
Hashs may add ( concatenate ) each other by extended “+” sign :
hFruits := { "fruits" => { "apple", "chery", "apricot" } }
hDays := { "days" => { "sunday", "monday" } }
hDoris := hFruits + hDays
Note: This “+” and “+=” operators depends xHB lib and needs to xHB lib and xHB.ch.
Typing :
<key> part of a hash may be any legal scalar type : C, D, L, N; and <value> part may be in addition scalar types, any complex type ( array or hash ).
Correction : This definition is wrong ! The correct is :
<key> entry key; can be of type: number, date, datetime, string, pointer.
Corrected at : 2015.12.08; thanks to Marek.
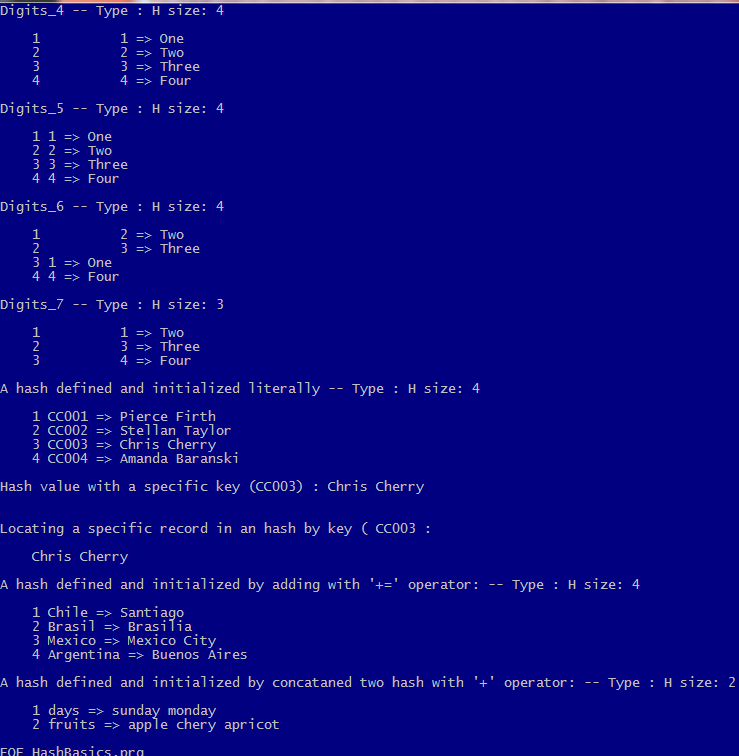
hDigits_2 := { 1 => “One”, 2 => “Two”, 3 => “Three”, 4 => “Four” }
hDigits_3 := { "1" => "One", "2" => "Two", "3" => "Three", "4" => "Four" }
hDigits_4 := { "1" => "One", 2 => "Two", 3 => "Three", "4" => "Four" }
hDigits_5 := { 1 => "One", 1 => "Two", 3 => "Three", 4 => "Four"
All of these examples are legal. As a result, a pair record of a hash may be:
– Numeric key, numeric value ( hDigits_1 )
– Numeric key, character value ( hDigits_2 )
– Character key, character value ( hDigits_3 )
– Mixed type key ( hDigits_4 )
Duplicate keys (as seen in hDigits_5) is permitted to assign, but not give a result such as double keyed values: LEN( hDigits_5 ) is 3, not 4; because first pair replaced by second due to has same key.
Consider a table-like data for customers records with two character fields: Customer ID and customer name:
| Cust_ID | Cust_Name |
| CC001 | Pierce Firth |
| CC002 | Stellan Taylor |
| CC003 | Chris Cherry |
| CC004 | Amanda Baranski |
We can build a hash with this data :
hCustomers := { "CC001" => "Pierce Firth",;
"CC002" => "Stellan Taylor",;
"CC003" => "Chris Cherry",;
"CC004" => "Amanda Baranski" }
and list it:
?
? "Listing a hash :"
?
h1Record := NIL
FOR EACH h1Record IN hCustomers
? cLMarj, h1Record:__ENUMKEY(), h1Record:__ENUMVALUE()
NEXT
Accessing a specific record is easy :
hCustomers[ "CC003" ] // Chris Cherry
*-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.
/*
Hash Basics
*/
#include "xhb.ch"
#define NTrim( n ) LTRIM( STR( n ) )
PROCEDURE Main()
SET DATE GERM
SET CENT ON
SET COLO TO "W/B"
cLMarj := SPACE( 3 )
CLS
hDigits_1 := { => } // Build an empty hash
hDigits_1[ 1 ] := 1
hDigits_1[ 2 ] := 2
hDigits_1[ 3 ] := 3
hDigits_1[ 4 ] := 4
ListHash( hDigits_1, "Digits_1" )
hDigits_2 := HB_HASH( 1, 1, 2, 2, 3, 3, 4, 4 )
ListHash( hDigits_2, "Digits_2" )
hDigits_3 := { 1 => 1,;
2 => 2,;
3 => 3,;
4 => 4 }
ListHash( hDigits_3, "Digits_3" )
hDigits_4 := { 1 => "One",;
2 => "Two",;
3 => "Three",;
4 => "Four" }
ListHash( hDigits_4, "Digits_4" )
hDigits_5 := { "1" => "One",;
"2" => "Two",;
"3" => "Three",;
"4" => "Four" }
ListHash( hDigits_5, "Digits_5" )
hDigits_6 := { "1" => "One",;
2 => "Two",;
3 => "Three",;
"4" => "Four" }
ListHash( hDigits_6, "Digits_6" )
hDigits_7 := { 1 => "One",;
1 => "Two",; // This line replace to previous due to same key
3 => "Three",;
4 => "Four" }
ListHash( hDigits_7, "Digits_7" )
* WAIT "EOF digits"
hCustomers := { "CC001" => "Pierce Firth",;
"CC002" => "Stellan Taylor",;
"CC003" => "Chris Cherry",;
"CC004" => "Amanda Baranski" }
ListHash( hCustomers, "A hash defined and initialized literally" )
?
? "Hash value with a specific key (CC003) :", hCustomers[ "CC003" ] // Chris Cherry
?
cKey := "CC003"
?
? "Locating a specific record in an hash by key (", cKey, ":"
?
c1Data := hCustomers[ cKey ]
? cLMarj, c1Data
hCountries := { 'Argentina' => "Buenos Aires" }
hCountries += { 'Brasil' => "Brasilia" }
hCountries += { 'Chile' => "Santiago" }
hCountries += { 'Mexico' => "Mexico City" }
ListHash( hCountries, "A hash defined and initialized by adding with '+=' operator:" )
hFruits := { "fruits" => { "apple", "chery", "apricot" } }
hDays := { "days" => { "sunday", "monday" } }
hDoris := hFruits + hDays
ListHash( hDoris, "A hash defined and initialized by concataned two hash with '+' operator:" )
?
@ MAXROW(), 0
WAIT "EOF HashBasics.prg"
RETURN // HashBasics.Main()
*-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.
PROCEDURE ListHash( hHash, cComment )
LOCAL x1Pair := NIL
cComment := IF( HB_ISNIL( cComment ), '', cComment )
?
? cComment, "-- Type :", VALTYPE( hHash ), "size:", NTrim ( LEN( hHash ) )
?
FOR EACH x1Pair IN hHash
nIndex := x1Pair:__ENUMINDEX()
x1Key := x1Pair:__ENUMKEY()
x1Value := x1Pair:__ENUMVALUE()
? cLMarj, NTrim( nIndex )
* ?? '', VALTYPE( x1Pair )
?? '', x1Key, "=>"
* ?? '', VALTYPE( x1Key )
* ?? VALTYPE( x1Value )
IF HB_ISARRAY( x1Value )
AEVAL( x1Value, { | x1 | QQOUT( '', x1 ) } )
ELSE
?? '', x1Value
ENDIF
NEXT
RETURN // ListHash()
*-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.