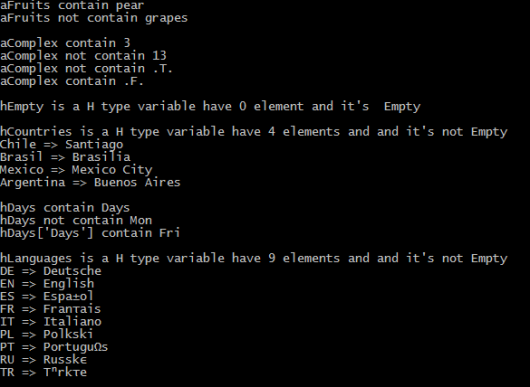
An array is a distinct data type which may contains multiple data items under same name. Data items stored in an array referred as an “element” and can be any data type. An individual element of array referenced by array name and position number of element as an integer in array, called “index” or “subscript”.
Defining / Building:
An array is a variable and like all variables has “scope”; arrays can be defined PRIVATE, PUBLIC and LOCAL as well as STATIC.
Building an array is quite simple: for example to define an array named “aColors” with 5 elements we can use a statement like this:
LOCAL aColors[ 5 ]
or
LOCAL aColors := ARRAY( 5 )
or
LOCAL aColors := { , , , , }
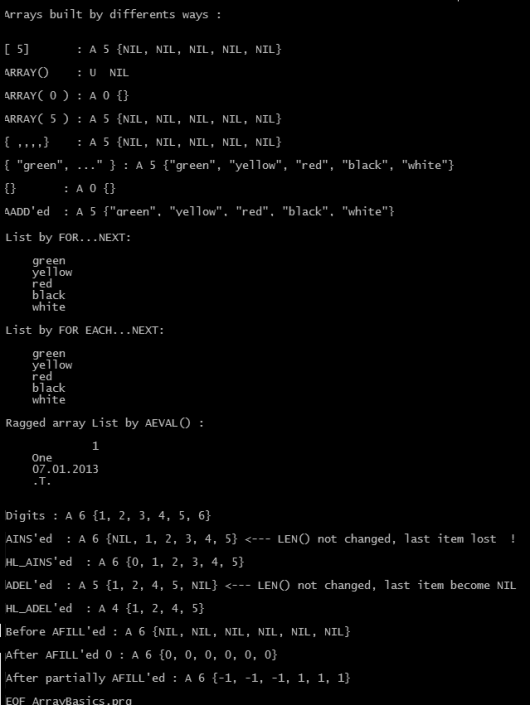
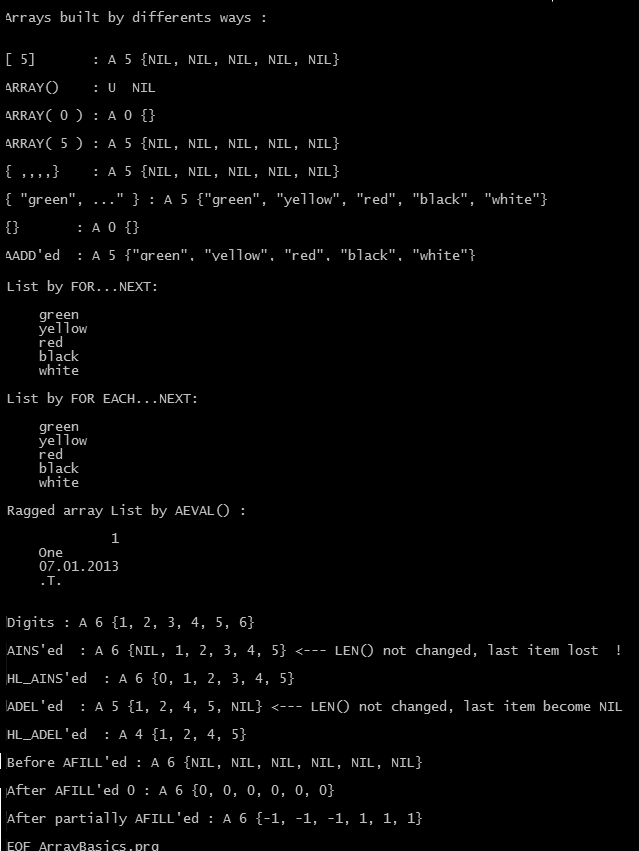
Results of these three methods are exactly same; we can inspect easily:
? ValType( aColors ) // A
? LEN( aColors ) // 5
? HB_ValToExp( aColors ) // {NIL, NIL, NIL, NIL, NIL}
NIL is a special data type with meaning “not defined”.
We can define an array with initial value(s)
aColors := { “green”, ”yellow” , “red”, “black”, “white” }
or assign values after defined:
aColors[ 1 ] := ”green”
aColors[ 2 ] := ”yellow”
aColors[ 3 ] := ”red”
aColors[ 4 ] := ”black”
aColors[ 5 ] := ”white”
? HB_ValToExp( aColors ) // {"green", "yellow", "red", "black", "white"}
Retrieve:
As seen in our first array statement
LOCAL aColors[ 5 ]
used a special sign square brackets as “Array element indicator” ( used also as string delimiter ).
As cited at the beginning, an individual element of array is referenced by array name and position number of element as an integer (enclosed by square brackets) in array, called “index” or “subscript”, and this notation called “subscripting”.
Note that subscribing begins with one.
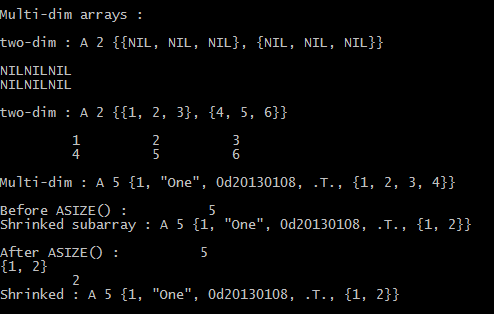
To specify more than one subscript ( i.e. when using multi-dimensional arrays), you can either enclose each subscript in a separate set of square brackets, or separate the subscripts with commas and enclose the list in square brackets. For example, if aArray is a two dimensional array, the following statements both addresses the second column element of tenth row:
aArray[ 10 ][ 2]
aArray[ 10, 2]
Of course it’s illegal to address an element that is outside of the boundaries of the array (lesser than one or greater than array size / length; one is also illegal for an empty array). Attempting to do so will result in a runtime error.
When making reference to an array element using a subscript, you are actually applying the subscript operator ([]) to an array expression, not only an array identifier (array variable name). An array expression is any valid expression that evaluate to an array. This includes function calls, variable references, subscripting operations, or any other expression that evaluate to an array. For example, the following are all valid:
{ “a”, “b”, “c” }[ 2 ]
x[ 2 ]
ARRAY(3)[ 2 ]
&(<macro expression>)[ 2 ]
(<complex expression>)[ 2 ]
Syntax :
<aArrayName> [ <nSubscript> ]
<nSubscript> is integer value and indicate sequence number of element into this array.
With this way we can also traverse an array:
FOR nColor := 1 TO LEN( aColors )
? aColors[ nColor ]
NEXT nColor
In fact, with the other FOR loop, traversing an array doesn’t require subscripting:
cColor := “” // FOR EACH loop require a predefined loop element
FOR EACH cColor IN aColors
? cColor
NEXT nColor
Elements of an array may be different data type; thus arrays called as “ragged” arrays in Clipper language.
aRagged := { 1, "One", DATE(), .T. }
FOR nIndex := 1 TO LEN( aRagged )
x1Elem := aRagged[ nIndex ]
? VALTYPE( x1Elem ), x1Elem
NEXT nIndex
A build-in array function AEVAL() can be use instead of a loop :
AEVAL( aRagged, { | x1 | QOUT(x1 ) } )
Adding one element to end of an array:
The architect of array is quite versatile. Array may change ( in size and element values ) dynamically at run time.
AADD() function can be used for add a new element to the end of an array
AADD(<aTarget>, <expValue>) --> Value
<aTarget> is the array to which a new element is to be added.
<expValue> is the value assigned to the new element.
AADD() is an array function that increases the actual length of the target array by one. The newly created array element is assigned the value specified by <expValue>.
AADD() is used to dynamically grow an array. It is useful for building dynamic lists or queues.
For example an array may build empty and later add element(s) to it :
aColors := {}
AADD( aColors, ”green” )
AADD( aColors, ”yellow” )
AADD( aColors, ”red” )
AADD( aColors, ”black” )
AADD( aColors, ”white” )
? HB_ValToExp( aColors ) // {"green", "yellow", "red", "black", "white"}
Inserting one element to an array:
AINS() function can be use for insert a NIL element into an array
AINS (<aTarget>, <nPosition>) --> aTarget
<aTarget> is the array into which a new element will be inserted.
<nPosition> is the position at which the new element will be inserted.
AINS() is an array function that inserts a new element into a specified array. The newly inserted element is NIL data type until a new value is assigned to it. After the insertion, the last element in the array is discarded, and all elements after the new element are shifted down one position.
For a lossless AINS() ( HL_AINS() ) look at attached .prg.
Deleting one element from an array:
ADEL(<aTarget>, <nPosition>) --> aTarget
ADEL() is an array function that deletes an element from an array. The content of the specified array element is lost, and all elements from that position to the end of the array are shifted up one element. The last element in the array becomes NIL. So, ADEL() function doesn’t change size of array.
For an another ADEL() ( HL_ADEL() ) look at attached .prg.
Resizing:
ASIZE() function can be use for grow or shrink, that is changing size of an array.
ASIZE( <aTarget>, <nLength>) --> aTarget
<aTarget> is the array to grow or shrink.
<nLength> is the new size of the array.
ASIZE() is an array function that changes the actual length of the <aTarget> array. The array is shortened or lengthened to match the specified length. If the array is shortened, elements at the end of the array are lost. If the array is lengthened, new elements are added to the end of the array and assigned NIL.
ASIZE() is similar to AADD() which adds a single new element to the end of an array and optionally assigns a new value at the same time. Note that ASIZE() is different from AINS() and ADEL(), which do not actually change the array’s length.
Assigning a fixed value to all elements of an array:
Changing values of all element of an array can not be accomplish by a simple assign statement. For example:
aTest := ARRAY( 3 )
aTest := 1
change type of aTest from array to numeric with a value 1.
Instead, AFILL() function gives a short way to fill an array with a fixed value.
AFILL() : Fill an array with a specified value
Syntax :
AFILL(<aTarget>, <expValue>,
[<nStart>], [<nCount>]) --> aTarget
<aTarget> is the array to be filled.
<expValue> is the value to be placed in each array element. It can be an expression of any valid data type.
<nStart> is the position of the first element to be filled. If this argument is omitted, the default value is one.
<nCount> is the number of elements to be filled starting with element <nStart>. If this argument is omitted, elements are filled from the starting element position to the end of the array.
Code evaluation on an array:
AEVAL()
Execute a code block for each element in an array
Syntax:
AEVAL(<aArray>, <bBlock>,
[<nStart>], [<nCount>]) --> aArray
Arguments:
<aArray> is the array to traverse.
<bBlock> is a code block to execute for each element encountered.
<nStart> is the starting element. If not specified, the default is element one.
<nCount> is the number of elements to process from <nStart>. If not specified, the default is all elements to the end of the array.
Returns:
AEVAL() returns a reference to <aArray>.
Description:
AEVAL() is an array function that evaluates a code block once for each element of an array, passing the element value and the element index as block parameters. The return value of the block is ignored. All elements in <aArray> are processed unless either the <nStart> or the <nCount> argument is specified.
AEVAL() makes no assumptions about the contents of the array elements it is passing to the block. It is assumed that the supplied block knows what type of data will be in each element.
AEVAL() is similar to DBEVAL() which applies a block to each record of a database file. Like DBEVAL(), AEVAL() can be used as a primitive for the construction of iteration commands for both simple and complex array structures.
Refer to the Code Blocks section in the “Basic Concepts” chapter of the Programming and Utilities Guide for more information on the theory and syntax of code blocks.
Examples :
This example uses AEVAL() to display an array of file names and file sizes returned from the DIRECTORY() function:
#include “Directry.ch”
//
LOCAL aFiles := DIRECTORY(“*.dbf”), nTotal := 0
AEVAL(aFiles, { | aDbfFile |;
QOUT( PADR(aDbfFile[F_NAME], 10), aDbfFile[F_SIZE]),;
nTotal += aDbfFile[F_SIZE])} )
//
?
? "Total Bytes:", nTotal
This example uses AEVAL() to build a list consisting of selected items from a multi-dimensional array:
#include "Directry.ch"
//
LOCAL aFiles := DIRECTORY("*.dbf"), aNames := {}
AEVAL(aFiles, { | file | AADD(aNames, file[F_NAME]) } )
This example changes the contents of the array element depending on a condition. Notice the use of the codeblock parameters:
LOCAL aArray[6]
AFILL(aArray,"old")
AEVAL(aArray,;
{|cValue,nIndex| IF( cValue == "old",;
aArray[nIndex] := "new",)})
Searching a value into an array :
ASCAN() : Scan an array for a value or until a block returns true (.T.)
Syntax:
ASCAN(<aTarget>, <expSearch>,
[<nStart>], [<nCount>]) --> nStoppedAt
Arguments:
<aTarget> is the array to be scanned.
<expSearch> is either a simple value to scan for, or a code block. If <expSearch> is a simple value it can be character, date, logical, or numeric type.
<nStart> is the starting element of the scan. If this argument is not specified, the default starting position is one.
<nCount> is the number of elements to scan from the starting position. If this argument is not specified, all elements from the starting element to the end of the array are scanned.
Returns:
ASCAN() returns a numeric value representing the array position of the last element scanned. If <expSearch> is a simple value, ASCAN() returns the position of the first matching element, or zero if a match is not found. If <expSearch> is a code block, ASCAN() returns the position of the element where the block returned true (.T.).
Description:
ASCAN() is an array function that scans an array for a specified value and operates like SEEK when searching for a simple value. The <expSearch> value is compared to the target array element beginning with the leftmost character in the target element and proceeding until there are no more characters left in <expSearch>. If there is no match, ASCAN() proceeds to the next element in the array.
Since ASCAN() uses the equal operator (=) for comparisons, it is sensitive to the status of EXACT. If EXACT is ON, the target array element must be exactly equal to the result of <expSearch> to match.
If the <expSearch> argument is a code block, ASCAN() scans the <aTarget> array executing the block for each element accessed. As each element is encountered, ASCAN() passes the element’s value as an argument to the code block, and then performs an EVAL() on the block. The scanning operation stops when the code block returns true (.T.), or ASCAN() reaches the last element in the array.
Examples:
This example demonstrates scanning a three-element array using simple values and a code block as search criteria. The code block criteria show how to perform a case-insensitive search:
aArray := { "Tom", "Mary", "Sue" }
? ASCAN(aArray, "Mary") // Result: 2
? ASCAN(aArray, "mary") // Result: 0
//
? ASCAN(aArray, { |x| UPPER(x) == "MARY" }) // Result: 2
This example demonstrates scanning for multiple instances of a search argument after a match is found:
LOCAL aArray := { "Tom", "Mary", "Sue","Mary" },;
nStart := 1
//
// Get last array element position
nAtEnd := LEN(aArray)
DO WHILE (nPos := ASCAN(aArray, "Mary", nStart)) > 0
? nPos, aArray[nPos]
//
// Get new starting position and test
// boundary condition
IF (nStart := ++nPos) > nAtEnd
EXIT
ENDIF
ENDDO
This example scans a two-dimensional array using a code block. Note that the parameter aVal in the code block is an array:
LOCAL aArr:={}
CLS
AADD(aArr,{"one","two"})
AADD(aArr,{"three","four"})
AADD(aArr,{"five","six"})
? ASCAN(aArr, {|aVal| aVal[2] == "four"}) // Returns 2
Sorting an array:
ASORT() : Sort an array
Syntax:
ASORT(<aTarget>, [<nStart>],
[<nCount>], [<bOrder>]) --> aTarget
Arguments:
<aTarget> is the array to be sorted.
<nStart> is the first element of the sort. If not specified, the default starting position is one.
<nCount> is the number of elements to be sorted. If not specified, all elements in the array beginning with the starting element are sorted.
<bOrder> is an optional code block used to determine sorting order. If not specified, the default order is ascending.
Returns:
ASORT() returns a reference to the <aTarget> array.
Description:
ASORT() is an array function that sorts all or part of an array containing elements of a single data type. Data types that can be sorted include character, date, logical, and numeric.
If the <bOrder> argument is not specified, the default order is ascending. Elements with low values are sorted toward the top of the array (first element), while elements with high values are sorted toward the bottom of the array (last element).
If the <bOrder> block argument is specified, it is used to determine the sorting order. Each time the block is evaluated; two elements from the target array are passed as block parameters. The block must return true (.T.) if the elements are in sorted order. This facility can be used to create a descending or dictionary order sort. See the examples below.
When sorted, character strings are ordered in ASCII sequence; logical values are sorted with false (.F.) as the low value; date values are sorted chronologically; and numeric values are sorted by magnitude.
Notes:
ASORT() is only guaranteed to produce sorted output (as defined by the block), not to preserve any existing natural order in the process.
Because multidimensional arrays are implemented by nesting sub-arrays within other arrays, ASORT() will not directly sort a multidimensional array. To sort a nested array, you must supply a code block which properly handles the sub-arrays.
Examples:
This example creates an array of five unsorted elements, sorts the array in ascending order, then sorts the array in descending order using a code block:
aArray := { 3, 5, 1, 2, 4 }
ASORT(aArray)
// Result: { 1, 2, 3, 4, 5 }
ASORT(aArray,,, { |x, y| x > y })
// Result: { 5, 4, 3, 2, 1 }
This example sorts an array of character strings in ascending order, independent of case. It does this by using a code block that converts the elements to uppercase before they are compared:
aArray := { "Fred", Kate", "ALVIN", "friend" }
ASORT(aArray,,, { |x, y| UPPER(x) < UPPER(y) })
This example sorts a nested array using the second element of each sub-array:
aKids := { {"Mary", 14}, {"Joe", 23}, {"Art", 16} }
aSortKids := ASORT(aKids,,, { |x, y| x[2] < y[2] })
Result:
{ {“Mary”, 14}, {“Art”, 16}, {“Joe”, 23} }
Last element in an array:
ATAIL() : Return the highest numbered element of an array
Syntax:
ATAIL(<aArray>) --> Element
Arguments:
<aArray> is the array.
Returns:
ATAIL() returns either a value or a reference to an array or object. The array is not changed.
Description:
ATAIL() is an array function that returns the highest numbered element of an array. It can be used in applications as shorthand for <aArray>[LEN(<aArray>)] when you need to obtain the last element of an array.
Examples:
The following example creates a literal array and returns that last element of the array:
aArray := {"a", "b", "c", "d"}
? ATAIL(aArray) // Result: d
Getting directory info:
ADIR() is a array function to obtain directory information. But it’s a compatibility function and therefore not recommended. It is superseded by the DIRECTORY() function which returns all file information in a multidimensional array.
A sample .prg : ArrayBasics.prg