AADD() Add a new element to the end of an array ABS() Return the absolute value of a numeric expression ACHOICE() Execute a pop-up menu ACLONE() Duplicate a nested or multidimensional array ACOPY() Copy elements from one array to another ADEL() Delete an array element ADIR()* Fill a series of arrays with directory information AEVAL() Execute a code block for each element in an array AFIELDS()* Fill arrays with the structure of the current database file AFILL() Fill an array with a specified value AINS() Insert a NIL element into an array ALERT() Display a simple modal dialog box ALIAS() Return a specified work area alias ALLTRIM() Remove leading and trailing spaces from a character string ALTD() Invoke the CA-Clipper debugger ARRAY() Create an uninitialized array of specified length ASC() Convert a character to its ASCII value ASCAN() Scan an array for a value or until a block returns true (.T.) ASIZE() Grow or shrink an array ASORT() Sort an array AT() Return the position of a substring within a character string ATAIL() Return the highest numbered element of an array BIN2I() Convert a 16-bit signed integer to a numeric value BIN2L() Convert a 32-bit signed integer to a numeric value BIN2W() Convert a 16-bit unsigned integer to a numeric value BOF() Determine when beginning of file is encountered BREAK() Branch out of a BEGIN SEQUENCE...END construct BROWSE()* Browse records within a window CDOW() Convert a date value to a character day of the week CHR() Convert an ASCII code to a character value CMONTH() Convert a date to a character month name COL() Return the screen cursor column position COLORSELECT() Activate attribute in current color settings CTOD() Convert a date string to a date value CURDIR() Return the current DOS directory DATE() Return the system date as a date value DAY() Return the day of the month as a numeric value DBAPPEND() Append a new record to the database in the current work area DBCLEARFIL() Clear a filter condition DBCLEARIND() Close all indexes for the current work area DBCLEARREL() Clear active relations DBCLOSEALL() Close all occupied work areas DBCLOSEAREA() Close a work area DBCOMMIT() Flush pending updates DBCOMMITALL() Flush pending updates in all work areas DBCREATE() Create a database file from a database structure array DBCREATEIND() Create an index file DBDELETE() Mark a record for deletion DBEDIT() Browse records in a table layout DBEVAL() Evaluate code block for each record matching scope/condition DBF()* Return current alias name DBFIELDINFO() Return and optionally change information about a field DBFILEGET() Insert the contents of a field into a file DBFILEPUT() Insert the contents of a file into a field DBFILTER() Return the current filter expression as a character string DBGOBOTTOM() Move to the last logical record DBGOTO() Position record pointer to a specific identity DBGOTOP() Move to the first logical record DBINFO() Return and optionally change database file information DBORDERINFO() Return and optionally change order and index file information DBRECALL() Reinstate a record marked for deletion DBRECORDINFO() Return and optionally change information about a record DBREINDEX() Recreate all active indexes for the current work area DBRELATION() Return the linking expression of a specified relation DBRLOCK() Lock the record at the current or specified identity DBRLOCKLIST() Return an array of the current lock list DBRSELECT() Return the target work area number of a relation DBRUNLOCK() Release all or specified record locks DBSEEK() Move to the record having the specified key value DBSELECTAR() Change the current work area DBSETDRIVER() Return the database driver and optionally set a new driver DBSETFILTER() Set a filter condition DBSETINDEX() Empty orders from an order bag into the order list DBSETORDER() Set the controlling order DBSETRELAT() Relate two work areas DBSKIP() Move relative to the current record DBSTRUCT() Create an array containing the structure of a database file DBUNLOCK() Release all locks for the current work area DBUNLOCKALL() Release all locks for all work areas DBUSEAREA() Use a database file in a work area DELETED() Return the deleted status of the current record DESCEND() Create a descending index key value DEVOUT() Write a value to the current device DEVOUTPICT() Write a value to the current device using a picture clause DEVPOS() Move the cursor or printhead to a new position DIRCHANGE() Change the current DOS directory DIRECTORY() Create an array of directory and file information DIRMAKE() Create a directory DIRREMOVE() Remove a directory DISKCHANGE() Change the current DOS disk drive DISKNAME() Return the current DOS drive DISKSPACE() Return the space available on a specified disk DISPBEGIN() Begin buffering screen output DISPBOX() Display a box on the screen DISPCOUNT() Return the number of pending DISPEND() requests DISPEND() Display buffered screen updates DISPOUT() Write a value to the display DOSERROR() Return the last DOS error number DOW() Convert a date value to a numeric day of the week DTOC() Convert a date value to a character string DTOS() Convert a date value to a string formatted as yyyymmdd EMPTY() Determine if the result of an expression is empty EOF() Determine when end of file is encountered ERRORBLOCK() Post a code block to execute when a runtime error occurs ERRORLEVEL() Set the CA-Clipper return code EVAL() Evaluate a code block EXP() Calculate e**x FCLOSE() Close an open binary file and write DOS buffers to disk FCOUNT() Return the number of fields in the current .dbf file FCREATE() Create and/or truncate a binary file to zero-length FERASE() Delete a file from disk FERROR() Test for errors after a binary file operation FIELD() Return a field name from the current database (.dbf) file FIELDBLOCK() Return a set-get code block for a given field FIELDGET() Retrieve the value of a field using the field position FIELDNAME() Return a field name from the current database (.dbf) file FIELDPOS() Return the position of a field in a work area FIELDPUT() Set the value of a field variable using the field position FIELDWBLOCK() Return a set-get code block for a field in a given work area FILE() Determine if files exist in the default directory or path FKLABEL()* Return function key name FKMAX()* Return number of function keys as a constant FLOCK() Lock an open and shared database file FOPEN() Open a binary file FOUND() Determine if the previous search operation succeeded FREAD() Read characters from a binary file into a buffer variable FREADSTR() Read characters from a binary file FRENAME() Change the name of a file FSEEK() Set a binary file pointer to a new position FWRITE() Write to an open binary file GETACTIVE() Return the currently active Get object GETAPPLYKEY() Apply a key to a Get object from within a reader GETDOSETKEY() Process SET KEY during GET editing GETENV() Retrieve the contents of a DOS environment variable GETPOSTVALID() Postvalidate the current Get object GETPREVALID() Prevalidate a Get object GETREADER() Execute standard READ behavior for a Get object HARDCR() Replace all soft carriage returns with hard carriage returns HEADER() Return the current database file header length I2BIN() Convert a CA-Clipper numeric to a 16-bit binary integer IF() Return the result of an expression based on a condition IIF() Return the result of an expression based on a condition INDEXEXT() Return index extension defined by the current database driver INDEXKEY() Return the key expression of a specified index INDEXORD() Return the order position of the controlling index INKEY() Extract a character from the keyboard buffer or a mouse event INT() Convert a numeric value to an integer ISALPHA() Determine if the leftmost character in a string is alphabetic ISCOLOR() Determine if the current computer has color capability ISDIGIT() Determine if the leftmost character in a string is a digit ISLOWER() Determine if the leftmost character is a lowercase letter ISPRINTER() Determine whether LPT1 is ready ISUPPER() Determine if the leftmost character in a string is uppercase L2BIN() Convert a CA-Clipper numeric value to a 32-bit binary integer LASTKEY() Return INKEY() value of last key extracted from the keyboard LASTREC() Determine the number of records in the current .dbf file LEFT() Extract substring beginning with first character in a string LEN() Return the length of a string or number of array elements LOG() Calculate the natural logarithm of a numeric value LOWER() Convert uppercase characters to lowercase LTRIM() Remove leading spaces from a character string LUPDATE() Return the last modification date of a database (.dbf) file MAX() Return the larger of two numeric or date values MAXCOL() Determine the maximum visible screen column MAXROW() Determine the maximum visible screen row MEMOEDIT() Display or edit character strings and memo fields MEMOLINE() Extract a line of text from a character string or memo field MEMOREAD() Return the contents of a disk file as a character string MEMORY() Determine the amount of available free pool memory MEMOSETSUPER() Set an RDD inheritance chain for the DBFMEMO database driver MEMOTRAN() Replace carriage return/linefeeds in character strings MEMOWRIT() Write a character string or memo field to a disk file MEMVARBLOCK() Return a set-get code block for a given memory variable MENUMODAL() Activate a top bar menu MIN() Return the smaller of two numeric or date values MLCOUNT() Count the number of lines in a character string or memo field MLCTOPOS() Return position of a string based on line and column position MLPOS() Determine the position of a line in a string or memo field MOD()* Return the dBASE III PLUS modulus of two numbers MONTH() Convert a date value to the number of the month MPOSTOLC() Return line/ column position of a string based on a position NETERR() Determine if a network command has failed NETNAME() Return the current workstation identification NEXTKEY() Read the pending key in the keyboard buffer NOSNOW() Toggle snow suppression ORDBAGEXT() Return the default order bag RDD extension ORDBAGNAME() Return the order bag name of a specific order ORDCOND() Specify conditions for ordering ORDCONDSET() Set the condition and scope for an order ORDCREATE() Create an order in an order bag ORDDESCEND() Return and optionally change the descending flag of an order ORDDESTROY() Remove a specified order from an order bag ORDFOR() Return the FOR expression of an order ORDISUNIQUE() Return the status of the unique flag for a given order ORDKEY() Return the key expression of an order ORDKEYADD() Add a key to a custom built order ORDKEYCOUNT() Return the number of keys in an order ORDKEYDEL() Delete a key from a custom built order ORDKEYGOTO() Move to a record specified by its logical record number ORDKEYNO() Get the logical record number of the current record ORDKEYVAL() Get key value of the current record from controlling order ORDLISTADD() Add orders to the order list ORDLISTCLEAR() Clear the current order list ORDLISTREBUI() Rebuild all orders in the order list of the current work area ORDNAME() Return the name of an order in the order list ORDNUMBER() Return the position of an order in the current order list ORDSCOPE() Set or clear the boundaries for scoping key values ORDSETFOCUS() Set focus to an order in an order list ORDSETRELAT() Relate a specified work area to the current work area ORDSKIPUNIQUE() Move record pointer to the next or previous unique key OS() Return the operating system name OUTERR() Write a list of values to the standard error device OUTSTD() Write a list of values to the standard output device PAD() Pad character, date, and numeric values with a fill character PCOL() Return the current column position of the printhead PCOUNT() Determine the position of the last actual parameter passed PROCLINE() Return source line number of current or previous activation PROCNAME() Return name of the current or previous procedure or function PROW() Return the current row position of the printhead QOUT() Display a list of expressions to the console RAT() Return the position of the last occurrence of a substring RDDLIST() Return an array of the RDDs RDDNAME() Return name of RDD active in current or specified work area RDDSETDEFAULT() Set or return the default RDD for the application READEXIT() Toggle Up arrow and Down arrow as READ exit keys READFORMAT() Return and optionally set code block to implement format file READINSERT() Toggle the current insert mode for READ and MEMOEDIT() READKEY()* Determine what key terminated a READ READKILL() Return and optionally set whether current READ can be exited READMODAL() Activate a full-screen editing mode for a GetList READUPDATED() Determine whether any GET variables changed during a READ READVAR() Return the current GET/MENU variable name RECCOUNT()* Determine the number of records in the current database file RECNO() Return the identity at the position of the record pointer RECSIZE() Determine the record length of a database (.dbf) file REPLICATE() Return a string repeated a specified number of times RESTSCREEN() Display a saved screen region to a specified location RIGHT() Return a substring beginning with the rightmost character RLOCK() Lock the current record in the active work area ROUND() Return a numeric value rounded to a specified number of digits ROW() Return the screen row position of the cursor RTRIM() Remove trailing spaces from a character string SAVESCREEN() Save a screen region for later display SCROLL() Scroll a screen region up or down, right or left SECONDS() Return the number of seconds elapsed since midnight SELECT() Determine the work area number of a specified alias SET() Inspect or change a system setting SETBLINK() Toggle * interpretation between blinking/background intensity SETCANCEL() Toggle Alt+C and Ctrl+Break as program termination keys SETCOLOR() Return the current colors and optionally set new colors SETCURSOR() Set the cursor shape SETKEY() Assign an action block to a key SETMODE() Change display mode to a specified number of rows and columns SETPOS() Move the cursor to a new position SETPRC() Set PROW() and PCOL() values SOUNDEX() Convert a character string to "soundex" form SPACE() Return a string of spaces SQRT() Return the square root of a positive number STR() Convert a numeric expression to a character string STRTRAN() Search and replace characters within a string or memo field STUFF() Delete and insert characters in a string SUBSTR() Extract a substring from a character string TIME() Return the system time TONE() Sound a speaker tone for a specified frequency and duration TRANSFORM() Convert any value into a formatted character string TRIM() Remove trailing spaces from a character string TYPE() Determine the type of an expression UPDATED() Determine whether a GET changed during a READ UPPER() Convert lowercase characters to uppercase USED() Determine whether a database file is in USE VAL() Convert a character number to numeric type VALTYPE() Determine the data type returned by an expression VERSION() Returns CA-Clipper version WORD()* Convert CALL command numeric parameters from double to int YEAR() Convert a date value to the year as a numeric value
Tag Archives: AEVAL()
C5_AEVAL
AEVAL()
Execute a code block for each element in an array
------------------------------------------------------------------------------
Syntax
AEVAL(<aArray>, <bBlock>,
[<nStart>], [<nCount>]) --> aArray
Arguments
<aArray> is the array to traverse.
<bBlock> is a code block to execute for each element encountered.
<nStart> is the starting element. If not specified, the default is
element one.
<nCount> is the number of elements to process from <nStart>. If not
specified, the default is all elements to the end of the array.
Returns
AEVAL() returns a reference to <aArray>.
Description
AEVAL() is an array function that evaluates a code block once for each
element of an array, passing the element value and the element index as
block parameters. The return value of the block is ignored. All
elements in <aArray> are processed unless either the <nStart> or the
<nCount> argument is specified.
AEVAL() makes no assumptions about the contents of the array elements it
is passing to the block. It is assumed that the supplied block knows
what type of data will be in each element.
AEVAL() is similar to DBEVAL() which applies a block to each record of a
database file. Like DBEVAL(), AEVAL() can be used as a primitive for
the construction of iteration commands for both simple and complex array
structures.
Refer to the Code Blocks section in the "Basic Concepts" chapter of the
Programming and Utilities Guide for more information on the theory and
syntax of code blocks.
Examples
. This example uses AEVAL() to display an array of file names
and file sizes returned from the DIRECTORY() function:
#include "Directry.ch"
//
LOCAL aFiles := DIRECTORY("*.dbf"), nTotal := 0
AEVAL(aFiles,;
{ | aDbfFile |;
QOUT(PADR(aDbfFile[F_NAME], 10), aDbfFile[F_SIZE]),;
nTotal += aDbfFile[F_SIZE]);
} )
//
?
? "Total Bytes:", nTotal
. This example uses AEVAL() to build a list consisting of
selected items from a multidimensional array:
#include "Directry.ch"
//
LOCAL aFiles := DIRECTORY("*.dbf"), aNames := {}
AEVAL(aFiles,;
{ | file | AADD(aNames, file[F_NAME]) };
)
. This example changes the contents of the array element
depending on a condition. Notice the use of the codeblock
parameters:
LOCAL aArray[6]
AFILL(aArray,"old")
AEVAL(aArray,;
{|cValue,nIndex| IF(cValue == "old",;
aArray[nIndex] := "new",)})
Files Library is CLIPPER.LIB.
See Also: DBEVAL() EVAL() QOUT()
OrdWildSeek()
OrdWildSeek()
Searches a value in the controlling index using wild card characters.
Syntax : OrdWildSeek( <cWildCardString>,;
[<lCurrentRec>] , ;
[<lBackwards>] ) --> lFound
Arguments :
<cWildCardString> :
This is a character string to search in the controlling index. It may include
the wild card characters "?" and "*". The question mark matches a single
character, while the asterisk matches one or more characters.
<lCurrentRec> :
This parameter defaults to .F. (false) causing OrdWildSeek() to begin the
search with the first record included in the controlling index. When .T.
(true) is passed, the function begins the search with the current record.
<lBackwards> :
If .T. (true) is passed, OrdWildSeek() searches <cWildCardString> towards
the begin of file. The default value is .F. (false), i.e. the function
searches towards the end of file.
Return :
The function returns .T. (true) if a record matching <cWildCardString> is
found in the controlling index, otherwise .F. (false) is returned.
Description :
OrdWildSeek() searches a character string that may include wild card
characters in the controlling index. This allows for collecting subsets
of records based on an approximate search string. Records matching the
search string are found in the controlling index, and the record pointer
is positioned on the found record.
When a matching record is found, the function Found() returns .T. (true)
until the record pointer is moved again. In addition, both functions,
BoF() and EoF() return .F. (false).
If the searched value is not found, OrdWildSeek() positions the record
pointer on the "ghost record" (Lastrec()+1), and the function Found()
returns .F. (false), while Eof() returns .T. (true). The SET SOFTSEEK
setting is ignored by OrdWildSeek().
Info :
See also: DbSeek(), LOCATE, OrdFindRec(), OrdKeyGoto(), WildMatch()
Category: Database functions, Index functions, extensions
Example :
// The example uses two wildcard search strings to show
// possible search results of OrdWildSeek()
PROCEDURE Main
LOCAL aCust := {}
USE Customer
INDEX ON Upper(LastName) TO Cust01
DO WHILE OrdWildSeek( "*MAN?", .T. )
AAdd( aCust, FIELD->Lastname )
ENDDO
AEval( aCust, {|c| QOut(c) } )
// Found records:
// Dormann
// Feldman
GO TOP
aCust := {}
DO WHILE OrdWildSeek( "*EL*", .T. )
AAdd( aCust, FIELD->Lastname )
ENDDO
AEval( aCust, {|c| QOut(c) } )
// Found records:
// Feldman
// Hellstrom
// Keller
// Reichel
USE
RETURN
Note : Harbour has this function without documentation. This page borrowed
from xHarbour and not tested. Please beware about Unicode.
Parsing Text – Tokens
/*
From Harbour changelog (at 2007-04-04 10:35 UTC+0200 By Przemyslaw Czerpak )
Added set of functions to manipulate string tokens:
HB_TOKENCOUNT( <cString>, [ <cDelim> ], [ <lSkipStrings> ],
[ <lDoubleQuoteOnly> ] ) -> <nTokens>
HB_TOKENGET( <cString>, <nToken>, [ <cDelim> ], [ <lSkipStrings> ],
[ <lDoubleQuoteOnly> ] ) -> <cToken>
HB_TOKENPTR( <cString>, @<nSkip>, [ <cDelim> ], [ <lSkipStrings> ],
[ <lDoubleQuoteOnly> ] ) -> <cToken>
HB_ATOKENS( <cString>, [ <cDelim> ], [ <lSkipStrings> ],
[ <lDoubleQuoteOnly> ] ) -> <aTokens>
All these functions use the same method of tokenization. They can
accept as delimiters string longer then one character. By default
they are using " " as delimiter. " " delimiter has special mening
Unlike other delimiters repeted ' ' characters does not create empty
tokens, f.e.:
HB_ATOKENS( " 1 2 3 " ) returns array:
{ "1", "2", "3" }
Any other delimiters are restrictly counted, f.e.:
HB_ATOKENS( ",,1,,2,") returns array:
{ "", "", "1", "", "2", "" }
And a strong suggession made at 2009-12-09 21:25 UTC+0100 ( By Przemyslaw Czerpak )
I strongly suggest to use hb_aTokens() and hb_token*() functions.
They have more options and for really large data many times
(even hundreds times) faster.
*/
#define CRLF HB_OsNewLine()
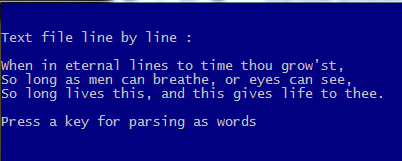
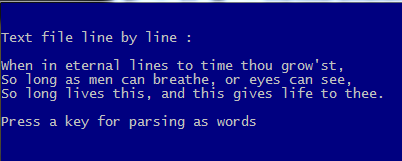
PROCEDURE Main()
LOCAL cTextFName := "Shakespeare.txt",;
c1Line
SET COLO TO "W/B"
SetMode( 40, 120 )
CLS
HB_MEMOWRIT( cTextFName,;
"When in eternal lines to time thou grow'st," + CRLF + ;
"So long as men can breathe, or eyes can see," + CRLF + ;
"So long lives this, and this gives life to thee." )
aLines := HB_ATOKENS( MEMOREAD( cTextFName ), CRLF )
?
? "Text file line by line :"
?
AEVAL( aLines, { | c1Line | QOUT( c1Line ) } )
?
WAIT "Press a key for parsing as words"
CLS
?
? "Text file word by word :"
?
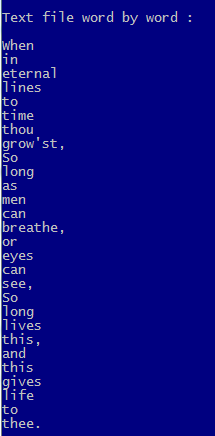
FOR EACH c1Line IN aLines
a1Line := HB_ATOKENS( c1Line )
AEVAL( a1Line, { | c1Word | QOUT( c1Word ) } )
NEXT
?
WAIT "Press a key for parsing directly as words"
CLS
?
? "Text file directly word by word :"
?
aWords := HB_ATOKENS( MEMOREAD( cTextFName ) )
AEVAL( aWords, { | c1Word | QOUT( c1Word ) } )
?
@ MAXROW(), 0
WAIT "EOF TP_Token.prg"
RETURN // TP_Token.Main()
Parsing Text – FParse()
/* FParse()
Parses a delimited text file and loads it into an array. Syntax :
FParse( <cFileName>, <cDelimiter> ) --> aTextArray
Arguments :
<cFileName> : This is a character string holding the name of the text file to load
into an array. It must include path and file extension.
If the path is omitted from <cFileName>,
the file is searched in the current directory.
<cDelimiter> : This is a single character used to parse a single line of text.
It defaults to the comma.
Return :
The function returns a two dimensional array, or an empty array when the file
cannot be opened.
Description :
Function FParse() reads a delimited text file and parses each line
of the file at <cDelimiter>. The result of line parsing is stored in an array.
This array, again, is collected in the returned array,
making it a two dimensional array
FParse() is mainly designed to read the comma-separated values (or CSV) file format,
were fields are separated with commas and records with new-line character(s).
Library is : xHb
*/
#define CRLF HB_OsNewLine()
PROCEDURE Main()
LOCAL cTextFName := "Shakespeare.txt",;
a1Line
SET COLO TO "W/B"
SetMode( 40, 120 )
CLS
HB_MEMOWRIT( cTextFName,;
"When in eternal lines to time thou grow'st," + CRLF + ;
"So long as men can breathe, or eyes can see," + CRLF + ;
"So long lives this, and this gives life to thee." )
aLines := FParse( cTextFName, " " )
?
? "Text file word by word :"
?
FOR EACH a1Line IN aLines
AEVAL( a1Line, { | c1Word | QOUT( c1Word ) } )
NEXT
?
@ MAXROW(), 0
WAIT "EOF TP_FParse.prg"
RETURN // TP_FParse.Main()

Hash vs Table
Consider a table for customers records with two character fields : Customer ID and customer name:
| Cust_ID | Cust_Name |
| CC001 | Pierce Firth |
| CC002 | Stellan Taylor |
| CC003 | Chris Cherry |
| CC004 | Amanda Baranski |
It’s known all possible and necessary operations on a table: APPEND, DELETE, SEEK and so on; by the way, for SEEK we need an index file also.
Listing this table is quite simple:
USE CUSTOMER
WHILE .NOT. EOF()
? CUST_ID, CUST_NAME
DBSKIP()
ENDDO
If our table is sufficiently small, we can find a customer record without index and SEEK :
LOCATE FOR CUST_ID = “CC003”
? CUST_ID, CUST_NAME
If we want all our data will stand in memory and we could manage it more simple and quick way, we would use an array ( with some considerations about size of table; if it is too big, this method will be problematic ) :
aCustomer := {} // Declare / define an empty array
USE CUSTOMER
WHILE .NOT. EOF()
AADD(aCustomer, { CUST_ID, CUST_NAME } )
DBSKIP()
ENDDO
Traversing this array is quite simple :
FOR nRecord := 1 TO LEN( aCustomer )
? aCustomer[ nRecord, 1 ], aCustomer[ nRecord, 2 ]
NEXT
or :
a1Record := {}
FOR EACH a1Record IN aCustomer
? a1Record[ 1 ], a1Record[ 2 ]
NEXT
And locating a specific record too:
nRecord := ASCAN( aCustomer, { | a1Record | a1Record[ 1 ] == “CC003” } )
? aCustomer[ nRecord, 1 ], aCustomer[ nRecord, 2 ]
A lot of array functions are ready to use for maintain this array : ADEL(), AADD(), AINS() etc …
Now, let’s see how we could use a hash for achieve this job :
hCustomer := { => } // Declare / define an empty hash
USE CUSTOMER
WHILE .NOT. EOF()
hCustomer[ CUST_ID ] := CUST_NAME
DBSKIP()
ENDDO
Let’s traversing :
h1Record := NIL
FOR EACH h1Record IN hCustomer
? h1Record: __ENUMKEY(),h1Record:__ENUMVALUE()
NEXT
Now, we have a bit complicate our job; a few field addition to the table :
| No: | Field Name | Type | Width | Dec | Decription |
|
1 |
CUST_ID |
C |
5 |
0 |
Id ( Code ) |
|
2 |
CUST_NAME |
C |
10 |
0 |
Name |
|
3 |
CUST_SNAM |
C |
10 |
0 |
Surname |
|
4 |
CUST_FDAT |
D |
8 |
0 |
First date |
|
5 |
CUST_ACTV |
L |
1 |
0 |
Is active ? |
|
6 |
CUST_BLNCE |
N |
11 |
2 |
Balance |
While <key> part of an element of a hash may be C / D / N / L type; <xValue> part of hash too may be ANY type of data, exactly same as arrays.
So, we can make fields values other than first ( ID) elements of an array:
hCustomer := { => } // Declare / define an empty hash
USE CUSTOMER
WHILE .NOT. EOF()
a1Data:= { CUST_NAME, CUST_SNAM, CUST_FDAT, CUST_ACTV, CUST_BLNCE }
hCustomer[ CUST_ID ] := a1Data
DBSKIP()
ENDDO
Let’s traversing :
h1Record := NIL
FOR EACH h1Record IN hCustomer
a1Key := h1Record:__ENUMKEY()
a1Data := h1Record:__ENUMVALUE()
? a1Key
AEVAL( a1Data, { | x1 | QQOUT( x1 ) } )
NEXT
*-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._
/*
Hash vs Tables
*/
#define NTrim( n ) LTRIM( STR( n ) )
#define cLMarj SPACE( 3 )
PROCEDURE Main()
SET DATE GERM
SET CENT ON
SET COLO TO "W/B"
SetMode( 40, 120 )
CLS
hCustomers := { => } // Declare / define an empty PRIVATE hash
IF MakUseTable()
Table2Hash()
* Here the hash hCustomers may be altered in any way
ZAP
Hash2Table()
ELSE
? "Couldn't make / USE table"
ENDIF
?
@ MAXROW(), 0
WAIT "EOF HashVsTable.prg"
RETURN // HashVsTable.Main()
*-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.
PROCEDURE Table2Hash()
hCustomers := { => }
WHILE .NOT. EOF()
hCustomers[ CUST_ID ] := CUST_SNAM
DBSKIP()
ENDDO
ListHash( hCustomers, "A hash transferred from a table (single value)" )
hCustomers := { => } // Declare / define an empty hash
DBGOTOP()
WHILE .NOT. EOF()
hCustomers[ CUST_ID ] := { CUST_NAME, CUST_SNAM, CUST_FDAT, CUST_ACTV, CUST_BLNCE }
DBSKIP()
ENDDO
ListHash( hCustomers, "A hash transferred from a table (multiple values)" )
RETURN // Table2Hash()
*-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.
PROCEDURE Hash2Table()
LOCAL h1Record,;
c1Key,;
a1Record,;
n1Field
FOR EACH h1Record IN hCustomers
c1Key := h1Record:__ENUMKEY()
a1Record := h1Record:__ENUMVALUE()
DBAPPEND()
FIELDPUT( 1, c1Key )
AEVAL( a1Record, { | x1, n1 | FIELDPUT( n1 + 1 , x1 ) } )
NEXT h1Record
DBGOTOP()
?
? "Data trasferred from hash to table :"
?
WHILE ! EOF()
? STR( RECN(), 5), ''
FOR n1Field := 1 TO FCOUNT()
?? FIELDGET( n1Field ), ''
NEXT n1Field
DBSKIP()
ENDDO
RETURN // Hash2Table()
*-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.
PROCEDURE ListHash( hHash, cComment )
LOCAL x1Pair
cComment := IF( HB_ISNIL( cComment ), '', cComment )
?
? cComment // , "-- Type :", VALTYPE( hHash ), "size:", LEN( hHash )
?
IF HB_ISHASH( hHash )
FOR EACH x1Pair IN hHash
nIndex := x1Pair:__ENUMINDEX()
x1Key := x1Pair:__ENUMKEY()
x1Value := x1Pair:__ENUMVALUE()
? cLMarj, NTrim( nIndex )
* ?? '', VALTYPE( x1Pair )
?? '', x1Key, "=>"
* ?? '', VALTYPE( x1Key )
* ?? VALTYPE( x1Value )
IF HB_ISARRAY( x1Value )
AEVAL( x1Value, { | x1 | QQOUT( '', x1 ) } )
ELSE
?? '', x1Value
ENDIF
NEXT
ELSE
? "Data type error; Expected hash, came", VALTYPE( hHash )
ENDIF HB_ISHASH( hHash )
RETURN // ListHash()
*-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.
FUNCTION MakUseTable() // Make / USE table
LOCAL cTablName := "CUSTOMER.DBF"
LOCAL lRetval, aStru, aData, a1Record
IF FILE( cTablName )
USE (cTablName)
ELSE
aStru := { { "CUST_ID", "C", 5, 0 },;
{ "CUST_NAME", "C", 10, 0 },;
{ "CUST_SNAM", "C", 10, 0 },;
{ "CUST_FDAT", "D", 8, 0 },;
{ "CUST_ACTV", "L", 1, 0 },;
{ "CUST_BLNCE", "N", 11, 2 } }
*
* 5-th parameter of DBCREATE() is alias -
* if not given then WA is open without alias
* ^^^^^^^^^^^^^
DBCREATE( cTablName, aStru, , .F., "CUSTOMER" )
aData := { { "CC001", "Pierce", "Firth", 0d20120131, .T., 150.00 },;
{ "CC002", "Stellan", "Taylor", 0d20050505, .T., 0.15 },;
{ "CC003", "Chris", "Cherry", 0d19950302, .F., 0 },;
{ "CC004", "Amanda", "Baranski", 0d20011112, .T., 12345.00 } }
FOR EACH a1Record IN aData
CUSTOMER->(DBAPPEND())
AEVAL( a1Record, { | x1, nI1 | FIELDPUT( nI1, X1 ) } )
NEXT a1Record
DBGOTOP()
ENDIF
lRetval := ( ALIAS() == "CUSTOMER" )
RETURN lRetval // MakUseTable()
*-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._


Array Basics
An array is a distinct data type which may contains multiple data items under same name. Data items stored in an array referred as an “element” and can be any data type. An individual element of array referenced by array name and position number of element as an integer in array, called “index” or “subscript”.
Defining / Building:
An array is a variable and like all variables has “scope”; arrays can be defined PRIVATE, PUBLIC and LOCAL as well as STATIC.
Building an array is quite simple: for example to define an array named “aColors” with 5 elements we can use a statement like this:
LOCAL aColors[ 5 ]
or
LOCAL aColors := ARRAY( 5 )
or
LOCAL aColors := { , , , , }
Results of these three methods are exactly same; we can inspect easily:
? ValType( aColors ) // A
? LEN( aColors ) // 5
? HB_ValToExp( aColors ) // {NIL, NIL, NIL, NIL, NIL}
NIL is a special data type with meaning “not defined”.
We can define an array with initial value(s)
aColors := { “green”, ”yellow” , “red”, “black”, “white” }
or assign values after defined:
aColors[ 1 ] := ”green”
aColors[ 2 ] := ”yellow”
aColors[ 3 ] := ”red”
aColors[ 4 ] := ”black”
aColors[ 5 ] := ”white”
? HB_ValToExp( aColors ) // {"green", "yellow", "red", "black", "white"}
Retrieve:
As seen in our first array statement
LOCAL aColors[ 5 ]
used a special sign square brackets as “Array element indicator” ( used also as string delimiter ).
As cited at the beginning, an individual element of array is referenced by array name and position number of element as an integer (enclosed by square brackets) in array, called “index” or “subscript”, and this notation called “subscripting”.
Note that subscribing begins with one.
To specify more than one subscript ( i.e. when using multi-dimensional arrays), you can either enclose each subscript in a separate set of square brackets, or separate the subscripts with commas and enclose the list in square brackets. For example, if aArray is a two dimensional array, the following statements both addresses the second column element of tenth row:
aArray[ 10 ][ 2] aArray[ 10, 2]
Of course it’s illegal to address an element that is outside of the boundaries of the array (lesser than one or greater than array size / length; one is also illegal for an empty array). Attempting to do so will result in a runtime error.
When making reference to an array element using a subscript, you are actually applying the subscript operator ([]) to an array expression, not only an array identifier (array variable name). An array expression is any valid expression that evaluate to an array. This includes function calls, variable references, subscripting operations, or any other expression that evaluate to an array. For example, the following are all valid:
{ “a”, “b”, “c” }[ 2 ]
x[ 2 ] ARRAY(3)[ 2 ] &(<macro expression>)[ 2 ] (<complex expression>)[ 2 ]
Syntax :
<aArrayName> [ <nSubscript> ]
<nSubscript> is integer value and indicate sequence number of element into this array.
With this way we can also traverse an array:
FOR nColor := 1 TO LEN( aColors ) ? aColors[ nColor ] NEXT nColor
In fact, with the other FOR loop, traversing an array doesn’t require subscripting:
cColor := “” // FOR EACH loop require a predefined loop element
FOR EACH cColor IN aColors ? cColor NEXT nColor
Elements of an array may be different data type; thus arrays called as “ragged” arrays in Clipper language.
aRagged := { 1, "One", DATE(), .T. }
FOR nIndex := 1 TO LEN( aRagged )
x1Elem := aRagged[ nIndex ]
? VALTYPE( x1Elem ), x1Elem
NEXT nIndex
A build-in array function AEVAL() can be use instead of a loop :
AEVAL( aRagged, { | x1 | QOUT(x1 ) } )
Adding one element to end of an array:
The architect of array is quite versatile. Array may change ( in size and element values ) dynamically at run time.
AADD() function can be used for add a new element to the end of an array
AADD(<aTarget>, <expValue>) --> Value
<aTarget> is the array to which a new element is to be added.
<expValue> is the value assigned to the new element.
AADD() is an array function that increases the actual length of the target array by one. The newly created array element is assigned the value specified by <expValue>.
AADD() is used to dynamically grow an array. It is useful for building dynamic lists or queues.
For example an array may build empty and later add element(s) to it :
aColors := {}
AADD( aColors, ”green” )
AADD( aColors, ”yellow” )
AADD( aColors, ”red” )
AADD( aColors, ”black” )
AADD( aColors, ”white” )
? HB_ValToExp( aColors ) // {"green", "yellow", "red", "black", "white"}
Inserting one element to an array:
AINS() function can be use for insert a NIL element into an array
AINS (<aTarget>, <nPosition>) --> aTarget
<aTarget> is the array into which a new element will be inserted.
<nPosition> is the position at which the new element will be inserted.
AINS() is an array function that inserts a new element into a specified array. The newly inserted element is NIL data type until a new value is assigned to it. After the insertion, the last element in the array is discarded, and all elements after the new element are shifted down one position.
For a lossless AINS() ( HL_AINS() ) look at attached .prg.
Deleting one element from an array:
ADEL(<aTarget>, <nPosition>) --> aTarget
ADEL() is an array function that deletes an element from an array. The content of the specified array element is lost, and all elements from that position to the end of the array are shifted up one element. The last element in the array becomes NIL. So, ADEL() function doesn’t change size of array.
For an another ADEL() ( HL_ADEL() ) look at attached .prg.
Resizing:
ASIZE() function can be use for grow or shrink, that is changing size of an array.
ASIZE( <aTarget>, <nLength>) --> aTarget
<aTarget> is the array to grow or shrink.
<nLength> is the new size of the array.
ASIZE() is an array function that changes the actual length of the <aTarget> array. The array is shortened or lengthened to match the specified length. If the array is shortened, elements at the end of the array are lost. If the array is lengthened, new elements are added to the end of the array and assigned NIL.
ASIZE() is similar to AADD() which adds a single new element to the end of an array and optionally assigns a new value at the same time. Note that ASIZE() is different from AINS() and ADEL(), which do not actually change the array’s length.
Assigning a fixed value to all elements of an array:
Changing values of all element of an array can not be accomplish by a simple assign statement. For example:
aTest := ARRAY( 3 ) aTest := 1
change type of aTest from array to numeric with a value 1.
Instead, AFILL() function gives a short way to fill an array with a fixed value.
AFILL() : Fill an array with a specified value
Syntax :
AFILL(<aTarget>, <expValue>,
[<nStart>], [<nCount>]) --> aTarget
<aTarget> is the array to be filled.
<expValue> is the value to be placed in each array element. It can be an expression of any valid data type.
<nStart> is the position of the first element to be filled. If this argument is omitted, the default value is one.
<nCount> is the number of elements to be filled starting with element <nStart>. If this argument is omitted, elements are filled from the starting element position to the end of the array.
Code evaluation on an array:
AEVAL()
Execute a code block for each element in an array
Syntax:
AEVAL(<aArray>, <bBlock>,
[<nStart>], [<nCount>]) --> aArray
Arguments:
<aArray> is the array to traverse.
<bBlock> is a code block to execute for each element encountered.
<nStart> is the starting element. If not specified, the default is element one.
<nCount> is the number of elements to process from <nStart>. If not specified, the default is all elements to the end of the array.
Returns:
AEVAL() returns a reference to <aArray>.
Description:
AEVAL() is an array function that evaluates a code block once for each element of an array, passing the element value and the element index as block parameters. The return value of the block is ignored. All elements in <aArray> are processed unless either the <nStart> or the <nCount> argument is specified.
AEVAL() makes no assumptions about the contents of the array elements it is passing to the block. It is assumed that the supplied block knows what type of data will be in each element.
AEVAL() is similar to DBEVAL() which applies a block to each record of a database file. Like DBEVAL(), AEVAL() can be used as a primitive for the construction of iteration commands for both simple and complex array structures.
Refer to the Code Blocks section in the “Basic Concepts” chapter of the Programming and Utilities Guide for more information on the theory and syntax of code blocks.
Examples :
This example uses AEVAL() to display an array of file names and file sizes returned from the DIRECTORY() function:
#include “Directry.ch”
//
LOCAL aFiles := DIRECTORY(“*.dbf”), nTotal := 0
AEVAL(aFiles, { | aDbfFile |;
QOUT( PADR(aDbfFile[F_NAME], 10), aDbfFile[F_SIZE]),;
nTotal += aDbfFile[F_SIZE])} )
//
?
? "Total Bytes:", nTotal
This example uses AEVAL() to build a list consisting of selected items from a multi-dimensional array:
#include "Directry.ch"
//
LOCAL aFiles := DIRECTORY("*.dbf"), aNames := {}
AEVAL(aFiles, { | file | AADD(aNames, file[F_NAME]) } )
This example changes the contents of the array element depending on a condition. Notice the use of the codeblock parameters:
LOCAL aArray[6]
AFILL(aArray,"old")
AEVAL(aArray,;
{|cValue,nIndex| IF( cValue == "old",;
aArray[nIndex] := "new",)})
Searching a value into an array :
ASCAN() : Scan an array for a value or until a block returns true (.T.)
Syntax:
ASCAN(<aTarget>, <expSearch>,
[<nStart>], [<nCount>]) --> nStoppedAt
Arguments:
<aTarget> is the array to be scanned.
<expSearch> is either a simple value to scan for, or a code block. If <expSearch> is a simple value it can be character, date, logical, or numeric type.
<nStart> is the starting element of the scan. If this argument is not specified, the default starting position is one.
<nCount> is the number of elements to scan from the starting position. If this argument is not specified, all elements from the starting element to the end of the array are scanned.
Returns:
ASCAN() returns a numeric value representing the array position of the last element scanned. If <expSearch> is a simple value, ASCAN() returns the position of the first matching element, or zero if a match is not found. If <expSearch> is a code block, ASCAN() returns the position of the element where the block returned true (.T.).
Description:
ASCAN() is an array function that scans an array for a specified value and operates like SEEK when searching for a simple value. The <expSearch> value is compared to the target array element beginning with the leftmost character in the target element and proceeding until there are no more characters left in <expSearch>. If there is no match, ASCAN() proceeds to the next element in the array.
Since ASCAN() uses the equal operator (=) for comparisons, it is sensitive to the status of EXACT. If EXACT is ON, the target array element must be exactly equal to the result of <expSearch> to match.
If the <expSearch> argument is a code block, ASCAN() scans the <aTarget> array executing the block for each element accessed. As each element is encountered, ASCAN() passes the element’s value as an argument to the code block, and then performs an EVAL() on the block. The scanning operation stops when the code block returns true (.T.), or ASCAN() reaches the last element in the array.
Examples:
This example demonstrates scanning a three-element array using simple values and a code block as search criteria. The code block criteria show how to perform a case-insensitive search:
aArray := { "Tom", "Mary", "Sue" }
? ASCAN(aArray, "Mary") // Result: 2
? ASCAN(aArray, "mary") // Result: 0
//
? ASCAN(aArray, { |x| UPPER(x) == "MARY" }) // Result: 2
This example demonstrates scanning for multiple instances of a search argument after a match is found:
LOCAL aArray := { "Tom", "Mary", "Sue","Mary" },;
nStart := 1
//
// Get last array element position
nAtEnd := LEN(aArray)
DO WHILE (nPos := ASCAN(aArray, "Mary", nStart)) > 0
? nPos, aArray[nPos]
//
// Get new starting position and test
// boundary condition
IF (nStart := ++nPos) > nAtEnd
EXIT
ENDIF
ENDDO
This example scans a two-dimensional array using a code block. Note that the parameter aVal in the code block is an array:
LOCAL aArr:={}
CLS
AADD(aArr,{"one","two"})
AADD(aArr,{"three","four"})
AADD(aArr,{"five","six"})
? ASCAN(aArr, {|aVal| aVal[2] == "four"}) // Returns 2
Sorting an array:
ASORT() : Sort an array
Syntax:
ASORT(<aTarget>, [<nStart>], [<nCount>], [<bOrder>]) --> aTarget
Arguments:
<aTarget> is the array to be sorted.
<nStart> is the first element of the sort. If not specified, the default starting position is one.
<nCount> is the number of elements to be sorted. If not specified, all elements in the array beginning with the starting element are sorted.
<bOrder> is an optional code block used to determine sorting order. If not specified, the default order is ascending.
Returns:
ASORT() returns a reference to the <aTarget> array.
Description:
ASORT() is an array function that sorts all or part of an array containing elements of a single data type. Data types that can be sorted include character, date, logical, and numeric.
If the <bOrder> argument is not specified, the default order is ascending. Elements with low values are sorted toward the top of the array (first element), while elements with high values are sorted toward the bottom of the array (last element).
If the <bOrder> block argument is specified, it is used to determine the sorting order. Each time the block is evaluated; two elements from the target array are passed as block parameters. The block must return true (.T.) if the elements are in sorted order. This facility can be used to create a descending or dictionary order sort. See the examples below.
When sorted, character strings are ordered in ASCII sequence; logical values are sorted with false (.F.) as the low value; date values are sorted chronologically; and numeric values are sorted by magnitude.
Notes:
ASORT() is only guaranteed to produce sorted output (as defined by the block), not to preserve any existing natural order in the process.
Because multidimensional arrays are implemented by nesting sub-arrays within other arrays, ASORT() will not directly sort a multidimensional array. To sort a nested array, you must supply a code block which properly handles the sub-arrays.
Examples:
This example creates an array of five unsorted elements, sorts the array in ascending order, then sorts the array in descending order using a code block:
aArray := { 3, 5, 1, 2, 4 }
ASORT(aArray)
// Result: { 1, 2, 3, 4, 5 }
ASORT(aArray,,, { |x, y| x > y })
// Result: { 5, 4, 3, 2, 1 }
This example sorts an array of character strings in ascending order, independent of case. It does this by using a code block that converts the elements to uppercase before they are compared:
aArray := { "Fred", Kate", "ALVIN", "friend" }
ASORT(aArray,,, { |x, y| UPPER(x) < UPPER(y) })
This example sorts a nested array using the second element of each sub-array:
aKids := { {"Mary", 14}, {"Joe", 23}, {"Art", 16} }
aSortKids := ASORT(aKids,,, { |x, y| x[2] < y[2] })
Result:
{ {“Mary”, 14}, {“Art”, 16}, {“Joe”, 23} }
Last element in an array:
ATAIL() : Return the highest numbered element of an array
Syntax:
ATAIL(<aArray>) --> Element
Arguments:
<aArray> is the array.
Returns:
ATAIL() returns either a value or a reference to an array or object. The array is not changed.
Description:
ATAIL() is an array function that returns the highest numbered element of an array. It can be used in applications as shorthand for <aArray>[LEN(<aArray>)] when you need to obtain the last element of an array.
Examples:
The following example creates a literal array and returns that last element of the array:
aArray := {"a", "b", "c", "d"}
? ATAIL(aArray) // Result: d
Getting directory info:
ADIR() is a array function to obtain directory information. But it’s a compatibility function and therefore not recommended. It is superseded by the DIRECTORY() function which returns all file information in a multidimensional array.
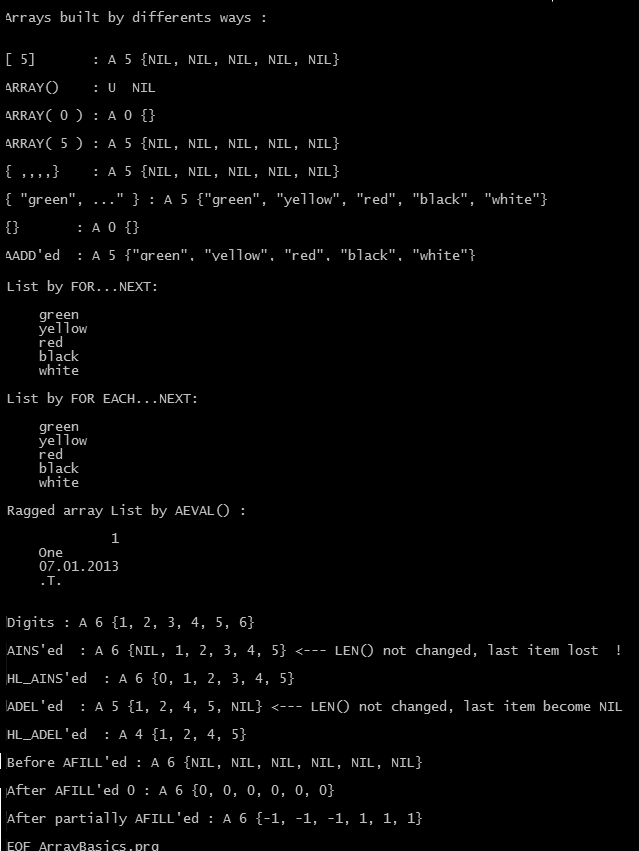
A sample .prg : ArrayBasics.prg
Operator overloading
/*
Operator overloading
Some operators overloaded by extending their functionalities.
"$" was an operator for "checking substring existence in a string"
For example :
? "A" $ "ABC" // Result: .T.
? "Z" $ "ABC" // Result: .F.
Now, this operator can be used for arrays and hashs too, not only strings.
See examples below.
"=>" was a preprocessor operator with meaning "translate to : ...".
Now, this operator can be used as a <key> - <value> separator in Hashs
for define and / or assign <key> - <value> to Hashs.
See examples below.
"[ ]" was Array element indicator (Special)
"{ }" was Literal array and code block delimiters (Special)
Now, this indicators can be used for hashs too.
See examples below.
"+=" is self-increment operator that can be used both numeric
and string values.
Such as :
cTest := "This"
cTest += " is"
? cTest // This is
nTest := 3
nTest += 10
? nTest // 13
Now, this operator can be used for adding elements to an existing hash;
( but no for arrays ! ).
Note : Extended functionalities of $ and += operators depends xHB lib.
So need this usages to xHB lib and xHB.ch.
See examples below.
*/
#include "xhb.ch"
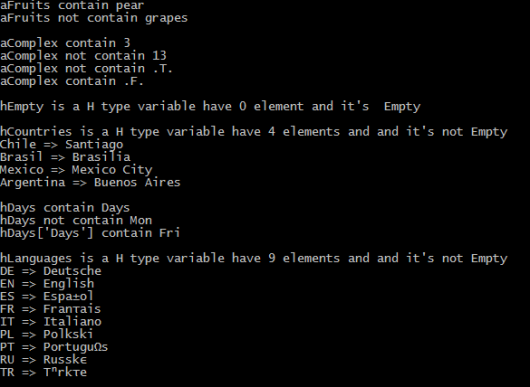
PROCEDURE Main()
CLS
aFruits := { "apple", "appricot", "cherry", "melon", "pear", "mulberry" }
? "aFruits", IF( "pear" $ aFruits, '', 'not ' ) + "contain pear"
? "aFruits", IF( "grapes" $ aFruits, '', 'not ' ) +"contain grapes"
aComplex := ARRAY( 10 )
AEVAL( aComplex, { | x1, i1 | aComplex[ i1 ] := i1 } )
aComplex[ 5 ] := DATE()
aComplex[ 7 ] := .F.
?
? "aComplex", IF( 3 $ aComplex, '', 'not ' ) + "contain 3"
? "aComplex", IF( 13 $ aComplex, '', 'not ' ) + "contain 13"
? "aComplex", IF( .T. $ aComplex, '', 'not ' ) + "contain .T."
? "aComplex", IF( .F. $ aComplex, '', 'not ' ) + "contain .F."
hEmpty := { => }
?
? "hEmpty is a", VALTYPE( hEmpty ), "type variable have",;
STR( LEN( hEmpty ), 1 ), "element and it's",;
IF( EMPTY( hEmpty ), '', 'not' ), "Empty"
hCountries := { 'Argentina' => "Buenos Aires" }
hCountries += { 'Brasil' => "Brasilia" }
hCountries += { 'Chile' => "Santiago" }
hCountries += { 'Mexico' => "Mexico City" }
?
? "hCountries is a", VALTYPE( hCountries ), "type variable have",;
STR( LEN( hCountries ), 1 ), "elements and and it's",;
IF( EMPTY( hCountries ), '', 'not' ), "Empty"
cCountry := NIL
FOR EACH cCountry IN hCountries
? cCountry:__ENUMKEY(), "=>", cCountry:__ENUMVALUE()
NEXT
hDays := { 'Days' => { "Mon", "Tue", "Wed", "Thu", "Fri", "Sat", "Sun" } }
?
? "hDays", IF( 'Days' $ hDays, '', 'not ' ) + "contain Days"
? "hDays", IF( "Mon" $ hDays, '', 'not ' ) + "contain Mon"
? "hDays['Days']", IF( "Fri" $ hDays["Days"], '', 'not ' ) + "contain Fri"
hLanguages := { "EN" => "English" } +;
{ "DE" => "Deutsche" } +;
{ "ES" => "Español" } +;
{ "FR" => "Français" } +;
{ "IT" => "Italiano" } +;
{ "PL" => "Polkski" } +;
{ "PT" => "Português" } +;
{ "RU" => "Russkî" } +;
{ "TR" => "Türkçe" }
?
? "hLanguages is a", VALTYPE( hLanguages ), "type variable have",;
STR( LEN( hLanguages ), 1 ), "elements and and it's",;
IF( EMPTY( hLanguages ), '', 'not' ), "Empty"
cLanguage := NIL
FOR EACH cLanguage IN hLanguages
? cLanguage:__ENUMKEY(), "=>", cLanguage:__ENUMVALUE()
NEXT
@ MAXROW(), 0
WAIT "EOF OprOLoad.prg"
RETURN // OprOLoad.Prg.Main()