Clipper 5.x – Drivers Guide
Chapter 2
Replaceable Database Driver Architecture
Clipper supports a driver architecture that allows Clipper applications to use Replaceable Database Drivers (RDDs). The RDD system makes Clipper applications data-format independent. Such applications can, therefore, access the data formats of other database systems, including the dBASE IV (.mdx), FoxPro (.cdx), and Paradox (.db) formats on a variety of equipment. This driver architecture can even support database drivers that are not file-based, although all of the drivers supplied with Clipper 5.x are file-based.
The concept of replaceable drivers is not new to this version of Clipper. In previous versions, the use of the default database driver (DBFNTX.LIB) was hidden by the fact that it was automatically linked into your application. In fact, this is still the case. The DBFNTX driver has been replaceable since it was first introduced in version 5.0. Before this version, the DBFNTX driver was the only RDD supplied as part of the system.
In This Chapter
With the introduction of the new RDDs, Clipper provides many new and enhanced commands and functions that access and manipulate databases. These language elements can enable your applications to access data regardless of the RDD under which it is ordered. There are also commands and functions that give you specific information about the RDDs in use.
The Language Implementation section of this chapter includes tables that summarize these new and enhanced language elements. This chapter also covers basic terminology, implementation principals, and general concepts of the Order Management System.
The following major topics are discussed:
. RDD Basics
. Basic Terminology
. The Language Implementation
. Order Management System
RDD Basics
The cornerstone of the replaceable database driver system is the Clipper work area. All Clipper database commands and functions operate in a work area through a database driver that actually performs the access to the stored database information. The layering of the system looks like this:
+———————————+
| Database Commands and Functions |
----------------------------------|
| RDD Interface |
|---------------------------------|
| Database driver |
|---------------------------------|
| Stored Data |
+---------------------------------+
In this system, each work area is associated with a single database driver. Each database driver, in turn, is supplied as a separate library file (.LIB) you link into your application programs. Within an application, you specify the name of the database driver when you open or access a database file or table with the USE command or DBUSEAREA() function. If you specify no database driver at the time a file is opened, the default driver is used. You may select which driver will be used as the default driver.
Once you open a database in a work area, the RDD used for that work area is automatically used for all operations on that database (except commands and functions that create a new table). Any command or function that creates a new table (i.e., SORT, CREATE FROM, DBCREATE(), etc.) uses the default RDD. Most of the new commands and functions let you specify a driver other than the default driver.
The normal default database driver, DBFNTX (which supports the traditional (.dbf), (.ntx), and (.dbt) files) is installed into your \CLIPPER5\LIB directory. This driver is linked into each program automatically to provide backwards compatibility.
To use any of the other supplied drivers, either as an additional driver or an alternate driver, you must use the REQUEST command to assure that the driver will be linked in. You must also include the appropriate library on the link line.
All Clipper applications will automatically include code generated by RDDSYS.PRG from the \CLIPPER5\SOURCE\SYS subdirectory. If you wish to automatically load another RDD, you must modify and compile RDDSYS.PRG and link the resulting object file into your application. The content of the default RDDSYS.PRG is shown below. Only the portion in bold should be modified
// Current RDDSYS.PRG
#include "rddsys.ch"
ANNOUNCE RDDSYS // This line must not change
INIT PROCEDURE RddInit
REQUEST DBFNTX // Force link for DBFNTX RDD
RDDSETDEFAULT( "DBFNTX" ) // Set up DBFNTX as default
// driver
RETURN
// eof: rddsys.prg
To change the default to a new automatically-loading driver, modify the bold lines in RDDSYS.PRG to include the name of the new driver. For example:
// Revised RDDSYS.PRG
#include "rddsys.ch"
ANNOUNCE RDDSYS // This line must not change
INIT PROCEDURE RddInit
REQUEST DBFCDX // Force link for DBFCDX RDD
RDDSETDEFAULT( "DBFCDX" ) // Set up DBFCDX as default
// driver
RETURN
// eof: rddsys.prg
If you change this file, all Clipper applications in which it is linked will automatically include the new RDD.
To use any RDD other than the default, you must explicitly identify it through use of the VIA clause of the USE command.
You need not disable the automatic DBFNTX loading to use other RDDs in your applications, but if your application will not use any DBFNTX functionality, you can save its code overhead by disabling it.
To completely disable the automatic loading of a default RDD, remove the two lines shown above in bold. For example:
// New Revised RDDSYS.PRG
// disables auto-loading
#include "rddsys.ch"
ANNOUNCE RDDSYS // This line must not change
INIT PROCEDURE RddInit
RETURN
// eof: rddsys.prg
Basic Terminology
The RDD architecture introduces several new terms and concepts that are key to the design and usage of RDDs. You should familiarize yourself with these concepts and terms as you begin to use the RDD functionality. The meaning of some earlier terminology is also further defined. The following RDD functional glossary defines the terminology for all RDDs.
. Key Expression : A valid Clipper expression that creates a key value from a single record.
. Key Value : A value that is based on value(s) contained within database fields, associated with a particular record in a database.
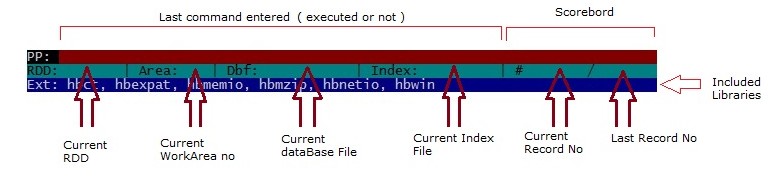
. Identity : A unique value guaranteed by the structure of the data file to reference a specific record in a database even if the record is empty. In the Xbase file (.dbf), the identity is the record number; but it could be the value of a unique primary key or even the offset of an array in memory.
. Keyed-Pair : A pair consisting of a key value and an identity.
. Identity Order : Describes a database arranged by identity. In Xbase, this refers to the physical arrangement of the records in the database in the order in which they were entered (natural order).
. Tag : A set of keyed-pairs that provides ordered access to the table based on a key value. Usually, an Order in a multiple-Order index (Order). An Order.
. Order : A named mechanism (index) that provides logical access to a database according to the keyed-pairs. This term encompasses both single indexes and the Tags in multiple-Tag indexes.
Orders are not, themselves, data files. They provide access to data that gives the appearance of an ordering of the data in a specific way. This ordering is defined by the relationships between keyed- pairs. An Order does not change the physical (the natural or entry) order of data in a database.
. Controlling Order : The active Order (index) for a particular work area. Only one Order may control a work area at any time, and it controls the order in which the database is accessed during paging and searching.
. Order List : A list of all the Orders available to the database in the specified work area.
. Order Bag : A container that holds zero or more Orders. Normally a disk or memory file. A traditional index like (.ntx) is an Order Bag that holds only one Order. A multiple-Tag index (.mdx or .cdx) is an Order Bag that holds zero or more Orders. Though Order Bags may be a memory or disk file, Clipper 5.x only supports Order Bags as disk files.
. Record : A record in the traditional database paradigm is a row of one or more related columns (fields) of data. In the expanded architecture of Clipper, a record could be data that does not exactly fit this definition.
A record is, in this expanded context, data associated with a single identity. In an Xbase data structure, this corresponds to a row (fields associated with a record number); in other data structures, this may not be the case.
In this document we use “record” in the traditional sense, but you should be aware that Clipper permits expansion of the meaning of record.
. single-Order Bag : An Order Bag that can contain only one Order. The (.ntx) and (.ndx) files are examples of single-Order Bags.
. multiple-Order Bag : An Order Bag that can contain any number of Orders; a multiple-Tag index. The (.cdx) and (.mdx) files are examples of multiple-Order Bags.
. maintainable scoped Orders : Scoped (filtered) Orders created using the FOR clause. The FOR condition is stored in the index header. Orders of this type are correctly updated using the expression to reflect record updates, deletions and additions.
. non-maintainable/temporary Orders : Orders created using the WHILE or NEXT clauses. These Orders are useful because they can be created quickly. However, the conditions in these clauses are not stored in the index header. Therefore, Orders of this type are not correctly updated to reflect record updates, deletions and additions. They are only for temporary use.
. Lock List : A list of the records that are currently locked in the work area.
The Language Implementation
To support the RDD architecture and let you design applications that are independent of the data format you are using, many existing Clipper commands and functions have been enhanced, and several new language elements have been added. The following tables summarize these changes and additions. See the Reference chapter of this guide for more detailed information on a particular item.
Enhanced Commands and Functions
------------------------------------------------------------------------
Command/Function Changes
------------------------------------------------------------------------
APPEND FROM VIA clause
COPY TO VIA clause
DBAPPEND() Terminology
GO Terminology
DBAPPEND() Terminology
INDEX ALL, EVAL, EVERY, NEXT, RECORD, REST, TAG, and
UNIQUE clauses
SEEK SOFTSEEK option
SET INDEX ADDITIVE clause
SET ORDER IN, TAG clauses
DBSETINDEX() Terminology
RECNO() Terminology
------------------------------------------------------------------------
New Commands and Functions
------------------------------------------------------------------------
Command/Function Description
------------------------------------------------------------------------
DELETE TAG Delete a Tag (Order)
DBGOTO() Position record pointer to a specific identity
DBRLOCK() Lock the record at the current or specified identity
DBRLOCKLIST() Return an array of the currently locked records
DBRUNLOCK Release all or specified record locks
ORDBAGEXT() Return the Order Bag file extension
ORDBAGNAME() Return the Order Bag name of a specific Order
ORDCREATE() Create an Order in an Order Bag
ORDDESTROY() Remove a specified Order from an Order Bag
ORDFOR() Return the FOR expression of an Order
ORDKEY() Return the Key expression of an Order
ORDLISTADD() Add Order Bag contents or single Order to the Order
List
ORDLISTCLEAR() Clear the current Order List
ORDLISTREBUILD() Rebuild all Orders in the Order List of the current
work area
ORDNAME() Return the name of an Order in the work area
ORDNUMBER() Return the position of an Order in the current Order
List
ORDSETFOCUS() Set focus to an Order in an Order List
RDDLIST() Return an array of the available Replaceable
Database Drivers
RDDNAME() Return the name of the RDD active in the current or
specified work area
RDDSETDEFAULT() Set or return the default RDD for the application
------------------------------------------------------------------------
User Interface Levels
We want to make it easy for you to quickly take advantage of the added functionality provided in Clipper 5.x. In order to effectively use the RDDs, you should read the following discussions. They are provided as a means of identifying the degree of programming knowledge or Clipper experience that will let you effectively use the RDD features.
For this purpose the RDD feature set is arbitrarily divided into levels A and B. Tables listing the commands or functions that comprise these access levels are also supplied. In addition, an RDD Features Summary is provided in table form which outlines the features available in each driver. The commands and functions in both of these levels of access are described in the Reference chapter of this guide.
Level A – Command-Level Interface
Level A. a simple command-level interface very similar to those found in other languages (e.g., dBASE IV, FoxPro). This is the primary access for new Clipper users who may or may not be familiar with other languages.
The following table lists the commands and functions accessible by the Clipper programmer with background in languages such as dBASE or FoxPro. The commands and functions in this table provide access to the additional features without requiring an advanced knowledge of Clipper or other programming concepts.
Basic Commands and Functions
------------------------------------------------------------------------
Command/Function Changes
------------------------------------------------------------------------
DELETE TAG Delete a Tag
GOTO Move the pointer to the specified identity
INDEX Create an index file
SEEK Search an Order for a specified key value
SET INDEX Open one or more Order Bags in the current work area
SET ORDER Select the controlling Order
DBAPPEND() Append a new record to the current Lock List
DBRLOCK() Lock the record at the current or specified identity
DBRLOCKLIST() Return an array of the current Lock List
DBRUNLOCK Release all or specified record locks
------------------------------------------------------------------------
Level B – Function-Level Interface
Level B. Clipper also adds a function level interface that not only allows access to the enhanced functionality of the drivers, but permits the building of higher-level functions using these composing behaviors. This level is meant for more experienced Clipper users who need to take advantage of the full power of the driver and Order Management System.
The following table lists the DML and Order Management functions recommended to the intermediate to advanced Clipper programmer. These functions provide the greatest flexibility in accessing the extended features of these drivers
Advanced Functions (including Order Management)
------------------------------------------------------------------------
Command/Function Description
------------------------------------------------------------------------
DBAPPEND() Append a new record to the current Lock List
DBRLOCK() Lock the record at the current or specified identity
DBRLOCKLIST() Return an array of the current Lock List
DBRUNLOCK() Release all or specified record locks
ORDBAGEXT() Return the default Order Bag RDD extension
ORDBAGNAME() Return the Order Bag name of a specific Order
ORDCREATE() Create an Order in an Order Bag
ORDDESTROY() Remove a specified Order from an Order Bag
ORDFOR() Return the FOR expression of an Order
ORDKEY() Return the Key expression of an Order
ORDLISTADD() Add Order Bag contents or single Order to the Order
List
ORDLISTCLEAR() Clear the current Order List
ORDLISTREBUILD() Rebuild all Orders in the Order List of the current
work area
ORDNAME() Return the name of an Order in the work area
ORDNUMBER() Return the position of an Order in the current Order
List
ORDSETFOCUS() Set focus to an Order in an Order List
RDDLIST() Return an array of the available Replaceable
Database Drivers
RDDNAME() Return the name of the RDD active in the current or
specified work area
RDDSETDEFAULT() Set or return the default RDD for the application
------------------------------------------------------------------------
RDD Features
The following decision table summarizes the availability of key features across RDDs. It lists the features available in each RDD so you can use it as an aid in correct RDD implementation and data access.
RDD Features Summary
------------------------------------------------------------------------
Item NTX NDX MDX CDX DBPX
------------------------------------------------------------------------
Implicit record unlocking in Yes Yes Yes Yes Yes
single lock mode
Multiple Record Locks Yes Yes Yes Yes No
Number of Concurrent Record Locks *1 *1 *1 *1 1
Order Management (Tag support) Yes Yes Yes Yes No
Orders (Tags) per Order Bag (File) 1 1 47 50 N/A
Number of Order Bags (Files) 15 15 15 15 N/A
per work area
Conditional Indexes (FOR clause) Yes No Yes Yes No
Temporary (Partial) Indexes Yes No No Yes No
(WHILE, ... )
Descending via DESCENDING clause Yes No Yes Yes No
Unique via the UNIQUE clause Yes Yes Yes Yes No
EVAL and EVERY clause support Yes No No Yes No
Production/Structural Indexes No No Yes Yes No
Maximum Key Expression length 256 256 220 255 N/A
(bytes)
Maximum FOR Condition length 256 N/A 261 255 N/A
(bytes)
------------------------------------------------------------------------
*1 determined by available memory.
Clipper 5.x Order Management
Clipper includes a new Order Management System which provides a more effective and flexible way of indexing data. The main objective of the new Order Management implementation is to raise the Xbase indexing paradigm from a low level of abstraction (Xbase database specific) to a higher, more robust, level. This higher level of abstraction allows the user to build new commands and functions.
Low level abstraction refers to manipulation of discrete elements in the database architecture (i.e., field names and sizes, methods of handling controlling indexes, etc.).
High level abstraction refers to manipulation of general elements in a data source. It lets us, for example, set a controlling Order without explicitly addressing the character of the data file structure. This higher level of abstraction was achieved by reviewing all the processes that indexes have in common.
The Order Management function set was generically named (i.e. non-dbf specific) to provide a semantic that could encompass future RDD implementations that may not be file-bound. For example, an RDD could easily be created that orders (indexes) on a memory array, or other data structure, instead of a database. Therefore, all Order Management functions simply begin with ORD (for Order). You will find the function names to be self-explanatory (e.g., ORDCREATE() creates an Order, and ORDDESTROY() destroys an Order).
Concept
An Order is a set of keyed-pairs that provides a logical ordering of the records in an associated database file. Each key in an Order (index) is associated with a particular identity (record number) in the data set (database file). The records can be processed sequentially in key order, and any record can be located by performing a SEEK operation with the associated key value. An Order never physically changes the data that it’s applied against, but creates a different view of that data.
There are at least four basic types of processes that you can perform with an Order:
1. Ordering: Changes the sequence in which you view the data records.
2. Scoping: Constrains the visibility of data to specified upper and lower bounds. Determines the range of data items included, through a scoping rule, like the WHILE clause.
3. Filtration: Visibility of data is subject to conditional evaluation. Filtration determines which items of data are included, through a filter rule, like the FOR clause.
4. Translation: Values in underlying data source are translated (or converted) in some form based on a selection criteria. For example:
INDEX ON IIF(CUSTID > 1000, "NEW", "OLD")
The difference between scope and condition as it applies to FOR and WHILE is that the WHILE clause provides scope, but not filtering, but a FOR clause can provide both.
There are three primary elements in Order Management:
. Order: An Order is a set that has two elements in it: an Order Name, which is a logical name that can be referenced, and an Order Expression which supplies the view of the data. The Order Name provides logical access to the expression and the Order Expression provides a way of viewing the underlying data source. Data ordering can also be modified to ascending or descending sequence.
– Order Name: An Order Name is a symbolic name, that you use to manipulate an Order, like a file’s alias. The difference between an Order Name and the Order Number with which you would normally access indexes (Orders), is that the Order Name is stored in the index file. It is available each time you run the program, and is maintained by the system. The Order Number is generated each time the Order is added to an Order List and may change from one program execution to another. This makes Order Name the preferred means of referencing Orders.
– Order Expression: Is any valid Clipper expression. This is an index expression such as:
CUSTLIST->CUSTID
This expression produces the ordered view of the data. The values derived from this expression are sorted, and it is the relationship of these values to one another that provides the actual ordering.
. Order Number: An Order Number is provided by the Order List. An Order Number is only valid as long as the work area to which it belongs is open.
– Order Numbers provide one of the services performed by Order Names, allowing you to access a specific Order. In general, you should avoid accessing Orders by number.
– The ORDNUMBER() function returns the ordinal position of the specified <orderName> within the specified <orderList>.
. Order Bag: Unsorted collection of Orders. Each Order contains two elements (Order Name and Order Expression). Each Order Bag may have zero to n Orders. The maximum is determined by the RDD driver being used. Order Bags are similar to multiple-index files in that there’s no guarantee of any specific order within the container or Bag. Within an Order Bag you can access specific Orders by referencing a particular Order Name. Order Bags have persistence between activations of the program.
. Order List: An Order List orders the collection of Orders that are associated with and active in the current work area. It provides an access to the Orders active within a given work area. Each work area has an Order List, and there is only one Order List per work area. An Order List is created when a new work area is opened, and exists only as long as that work area is active. Once you close a work area, the Order List ceases to exist.
When you SET INDEX TO, the contents of the Order Bag are emptied into the Order List. At this point, the Orders in the Order List are active in the work area, where they will be updated as the data associated with the work area is modified. You may access an Order in the list by its Order Number or by its Order Name. You should access an Order by its name rather than a hard-coded ordinal position. You can make any Order in the Order List the controlling Order by giving it focus, as explained below.
. Order List Focus: Order List Focus is, essentially, a pointer to the Order that is used to change the view of the data. It is synonymous with controlling Order or controlling index, and defines the active index order. The SET ORDER TO command does not modify the Order List in any way. It does not clear the active indexes. It only changes the Order List Focus (the controlling order in the Order List).
Notes
The following list contains specific information regarding Order Bag usage and limitations with DBFNDX and DBFNTX index files:
. Single-Order Bags: With DBFNDX and DBFNTX you can explicitly assign the Order Name within the Order creation syntax. You can then use the Order Name in any command or function that accepts an Order Name (Tag) as a parameter.
. Single-Order Bag with INDEX ON: Single-Order Bags may retain the Order Name between activations. During creation, DBFNTX stores an optionally supplied Order Name in the file’s header for subsequent use. Therefore, the Order Name is not necessarily the same as that of the file. By contrast, DBFNDX cannot store an Order Name since this would prevent dBASE from accessing the file. By default DBFNDX Orders inherit the name of their index file.
Summary
This chapter has introduced you to the RDD concept, giving you specific information on the architecture that implements RDDs in Clipper. The basic terminology of RDDs has also been defined.
Finally, you have seen an overview of the language enhancements designed to make using RDDs straightforward and to let you build applications that do not depend on the RDD in use. The next chapter elaborates on these language enhancements, discussing syntax and usage in detail.