HB_HCLONE()
Creates a copy of a hash table
Syntax
HB_HCLONE( <hsTable> ) -> <hsDestination>
Arguments
<hsTable> a hash table, created by HB_HASH()
Returns
A cloned copy of the hash table
Compliance
Harbour
Creates a copy of a hash table
Syntax
HB_HCLONE( <hsTable> ) -> <hsDestination>
Arguments
<hsTable> a hash table, created by HB_HASH()
Returns
A cloned copy of the hash table
Compliance
Harbour
Sets the ‘case match’ flag for the hash table
Syntax
HB_HCASEMATCH( <hsTable>, [<lFlag>] ) -> <lPreviousFlag>
Arguments
<hsTable> a hash table, created by HB_HASH()
<lFlag> a logical value indicating to turn on or off the ‘case match’ flag of the hash table
Returns
The previous value of the ‘case match’ flag
Description
This function is equivalent to HB_HSETCASEMATCH() but it returns the old flag value rather than the hash table
Examples
LOCAL hsTable, lFlag
hsTable := { "one" => 1, "two" => 2 }
// turn 'case match' on for a new hash table, storing ol flag
lFlag := hb_HCaseMatch( hsTable, .T. )
Compliance
Harbour
Seealso
HB_HSETCASEMATCH()
Sets the ‘binary’ flag for the hash table
Syntax
HB_HBINARY( <hsTable>, [<lFlag>] ) -> <lPreviousFlag>
Arguments
<hsTable> a hash table, created by HB_HASH()
<lFlag> a logical value indicating to turn on or off the ‘binary’ flag of the hash table
Returns
The previous value of the ‘binary’ flag
Description
This function is equivalent to HB_HBINARY() but it returns the old flag value rather than the hash table
Examples
LOCAL hsTable, lFlag
hsTable := { "one" => 1, "two" => 2 }
// turn 'binary' on for a new hash table, storing ol flag
lFlag := hb_HBinary( hsTable, .T. )
Compliance
Harbour
Seealso
HB_HSETBINARY()
Sets the ‘auto add’ flag for the hash table
Syntax
HB_HAUTOADD( <hsTable>, [<lFlag>] ) -> <lPreviousFlag>
Arguments
<hsTable> a hash table, created by HB_HASH()
<lFlag> a logical value indicating to turn on or off the ‘auto add’ flag of the hash table
Returns
The previous value of the ‘auto add’ flag
Description
This function is equivalent to HB_HAUTOADD() but it returns the old flag value rather than the hash table
Examples
LOCAL hsTable, lFlag
hsTable := { "one" => 1, "two" => 2 }
// turn 'auto add' on for a new hash table, storing ol flag
lFlag := hb_HAutoAdd( hsTable, .T. )
Compliance
Harbour
Seealso
HB_HSETAUTOADD()
Returns a hash table
Syntax
HB_HASH( [ <Key1>, <Value1> ], [ <KeyN>, <ValueN> ], ... ) -> hsTable
Arguments
<Key1> entry key; can be of type: number, date, datetime, string, pointer
<Value1> entry value; can be of type: block, string, numeric, date/datetime, logical, nil, pointer, array, hash table
Returns
A hash table built from the initial key/value pairs
Compliance
Harbour
*-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.
/*
Since a <Value> of a hash's pair may be in any scalar or complex type,
a hash may be nested by assigning an another hash to a hash <Value>.
*/
PROCEDURE Main()
SET COLO TO "W/B"
SetMode( 50, 120 )
CLS
hSouth := { 'Argentina' => "Buenos Aires",;
'Brasil' => "Brasilia",;
'Chile' => "Santiago" }
hNorth:= { 'USA' => "Washington DC",;
'Canada' => "Ottawa",;
'Mexico' => "Mexico City" }
* a hash contains two hashes :
hAmerica := { "America" => { "North" => hNorth,;
"South" => hSouth } }
* Standart array indexing syntax :
? hAmerica[ "America", "North", "USA" ] // Washington DC
* Alternate syntax to indexing :
? hAmerica[ "America"][ "South" ][ "Chile" ] // Santiago
?
@ MAXROW(), 0
WAIT "EOF HashNest.prg"
RETURN // HashNest.Main()
*-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.
Consider a table for customers records with two character fields : Customer ID and customer name:
| Cust_ID | Cust_Name |
| CC001 | Pierce Firth |
| CC002 | Stellan Taylor |
| CC003 | Chris Cherry |
| CC004 | Amanda Baranski |
It’s known all possible and necessary operations on a table: APPEND, DELETE, SEEK and so on; by the way, for SEEK we need an index file also.
Listing this table is quite simple:
USE CUSTOMER
WHILE .NOT. EOF()
? CUST_ID, CUST_NAME
DBSKIP()
ENDDO
If our table is sufficiently small, we can find a customer record without index and SEEK :
LOCATE FOR CUST_ID = “CC003”
? CUST_ID, CUST_NAME
If we want all our data will stand in memory and we could manage it more simple and quick way, we would use an array ( with some considerations about size of table; if it is too big, this method will be problematic ) :
aCustomer := {} // Declare / define an empty array
USE CUSTOMER
WHILE .NOT. EOF()
AADD(aCustomer, { CUST_ID, CUST_NAME } )
DBSKIP()
ENDDO
Traversing this array is quite simple :
FOR nRecord := 1 TO LEN( aCustomer )
? aCustomer[ nRecord, 1 ], aCustomer[ nRecord, 2 ]
NEXT
or :
a1Record := {}
FOR EACH a1Record IN aCustomer
? a1Record[ 1 ], a1Record[ 2 ]
NEXT
And locating a specific record too:
nRecord := ASCAN( aCustomer, { | a1Record | a1Record[ 1 ] == “CC003” } )
? aCustomer[ nRecord, 1 ], aCustomer[ nRecord, 2 ]
A lot of array functions are ready to use for maintain this array : ADEL(), AADD(), AINS() etc …
Now, let’s see how we could use a hash for achieve this job :
hCustomer := { => } // Declare / define an empty hash
USE CUSTOMER
WHILE .NOT. EOF()
hCustomer[ CUST_ID ] := CUST_NAME
DBSKIP()
ENDDO
Let’s traversing :
h1Record := NIL
FOR EACH h1Record IN hCustomer
? h1Record: __ENUMKEY(),h1Record:__ENUMVALUE()
NEXT
Now, we have a bit complicate our job; a few field addition to the table :
| No: | Field Name | Type | Width | Dec | Decription |
|
1 |
CUST_ID |
C |
5 |
0 |
Id ( Code ) |
|
2 |
CUST_NAME |
C |
10 |
0 |
Name |
|
3 |
CUST_SNAM |
C |
10 |
0 |
Surname |
|
4 |
CUST_FDAT |
D |
8 |
0 |
First date |
|
5 |
CUST_ACTV |
L |
1 |
0 |
Is active ? |
|
6 |
CUST_BLNCE |
N |
11 |
2 |
Balance |
While <key> part of an element of a hash may be C / D / N / L type; <xValue> part of hash too may be ANY type of data, exactly same as arrays.
So, we can make fields values other than first ( ID) elements of an array:
hCustomer := { => } // Declare / define an empty hash
USE CUSTOMER
WHILE .NOT. EOF()
a1Data:= { CUST_NAME, CUST_SNAM, CUST_FDAT, CUST_ACTV, CUST_BLNCE }
hCustomer[ CUST_ID ] := a1Data
DBSKIP()
ENDDO
Let’s traversing :
h1Record := NIL
FOR EACH h1Record IN hCustomer
a1Key := h1Record:__ENUMKEY()
a1Data := h1Record:__ENUMVALUE()
? a1Key
AEVAL( a1Data, { | x1 | QQOUT( x1 ) } )
NEXT
*-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._
/*
Hash vs Tables
*/
#define NTrim( n ) LTRIM( STR( n ) )
#define cLMarj SPACE( 3 )
PROCEDURE Main()
SET DATE GERM
SET CENT ON
SET COLO TO "W/B"
SetMode( 40, 120 )
CLS
hCustomers := { => } // Declare / define an empty PRIVATE hash
IF MakUseTable()
Table2Hash()
* Here the hash hCustomers may be altered in any way
ZAP
Hash2Table()
ELSE
? "Couldn't make / USE table"
ENDIF
?
@ MAXROW(), 0
WAIT "EOF HashVsTable.prg"
RETURN // HashVsTable.Main()
*-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.
PROCEDURE Table2Hash()
hCustomers := { => }
WHILE .NOT. EOF()
hCustomers[ CUST_ID ] := CUST_SNAM
DBSKIP()
ENDDO
ListHash( hCustomers, "A hash transferred from a table (single value)" )
hCustomers := { => } // Declare / define an empty hash
DBGOTOP()
WHILE .NOT. EOF()
hCustomers[ CUST_ID ] := { CUST_NAME, CUST_SNAM, CUST_FDAT, CUST_ACTV, CUST_BLNCE }
DBSKIP()
ENDDO
ListHash( hCustomers, "A hash transferred from a table (multiple values)" )
RETURN // Table2Hash()
*-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.
PROCEDURE Hash2Table()
LOCAL h1Record,;
c1Key,;
a1Record,;
n1Field
FOR EACH h1Record IN hCustomers
c1Key := h1Record:__ENUMKEY()
a1Record := h1Record:__ENUMVALUE()
DBAPPEND()
FIELDPUT( 1, c1Key )
AEVAL( a1Record, { | x1, n1 | FIELDPUT( n1 + 1 , x1 ) } )
NEXT h1Record
DBGOTOP()
?
? "Data trasferred from hash to table :"
?
WHILE ! EOF()
? STR( RECN(), 5), ''
FOR n1Field := 1 TO FCOUNT()
?? FIELDGET( n1Field ), ''
NEXT n1Field
DBSKIP()
ENDDO
RETURN // Hash2Table()
*-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.
PROCEDURE ListHash( hHash, cComment )
LOCAL x1Pair
cComment := IF( HB_ISNIL( cComment ), '', cComment )
?
? cComment // , "-- Type :", VALTYPE( hHash ), "size:", LEN( hHash )
?
IF HB_ISHASH( hHash )
FOR EACH x1Pair IN hHash
nIndex := x1Pair:__ENUMINDEX()
x1Key := x1Pair:__ENUMKEY()
x1Value := x1Pair:__ENUMVALUE()
? cLMarj, NTrim( nIndex )
* ?? '', VALTYPE( x1Pair )
?? '', x1Key, "=>"
* ?? '', VALTYPE( x1Key )
* ?? VALTYPE( x1Value )
IF HB_ISARRAY( x1Value )
AEVAL( x1Value, { | x1 | QQOUT( '', x1 ) } )
ELSE
?? '', x1Value
ENDIF
NEXT
ELSE
? "Data type error; Expected hash, came", VALTYPE( hHash )
ENDIF HB_ISHASH( hHash )
RETURN // ListHash()
*-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.
FUNCTION MakUseTable() // Make / USE table
LOCAL cTablName := "CUSTOMER.DBF"
LOCAL lRetval, aStru, aData, a1Record
IF FILE( cTablName )
USE (cTablName)
ELSE
aStru := { { "CUST_ID", "C", 5, 0 },;
{ "CUST_NAME", "C", 10, 0 },;
{ "CUST_SNAM", "C", 10, 0 },;
{ "CUST_FDAT", "D", 8, 0 },;
{ "CUST_ACTV", "L", 1, 0 },;
{ "CUST_BLNCE", "N", 11, 2 } }
*
* 5-th parameter of DBCREATE() is alias -
* if not given then WA is open without alias
* ^^^^^^^^^^^^^
DBCREATE( cTablName, aStru, , .F., "CUSTOMER" )
aData := { { "CC001", "Pierce", "Firth", 0d20120131, .T., 150.00 },;
{ "CC002", "Stellan", "Taylor", 0d20050505, .T., 0.15 },;
{ "CC003", "Chris", "Cherry", 0d19950302, .F., 0 },;
{ "CC004", "Amanda", "Baranski", 0d20011112, .T., 12345.00 } }
FOR EACH a1Record IN aData
CUSTOMER->(DBAPPEND())
AEVAL( a1Record, { | x1, nI1 | FIELDPUT( nI1, X1 ) } )
NEXT a1Record
DBGOTOP()
ENDIF
lRetval := ( ALIAS() == "CUSTOMER" )
RETURN lRetval // MakUseTable()
*-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._

Definition:
In general, a Hash Table, or Hash Array, or Associative array, or shortly Hash is an array- like data structure, to store some data with an associated key for each; so, ‘atom’ of a hash is a pair of a ‘key’ with a ‘value’. A hash system needs to perform at least three operations:
– add a new pair,
– access to value via key
– the search and delete operations on a key pair
In Harbour, a hash is simply a special array, or more precisely a “keyed” array with special syntax with a set of functions.
Building:
The “=>” operator can be used to indicate literally the relation between <key> <value> pair: <key> => <value>
We can define and initialize a hash by this “literal” way :
hDigits_1 := { 1 => 1, 2 => 2, 3 => 3, 4 => 4 }
or by a special function call:
hDigits_1 := HB_HASH( 1, 1, 2, 2, 3, 3, 4, 4 )
Using “add” method may be another way :
hDigits_1 := { => } // Build an empty hash
hDigits_1[ 1] := 1
hDigits_1[ 2] := 2
hDigits_1[ 3] := 3
hDigits_1[ 4] := 4
In this method while evaluating each of above assignments, if given key exits in hash, will be replaced its value; else add a new pair to the hash.
In addition, data can be added to a hash by extended “+=” operator:
hCountries := { 'Argentina' => "Buenos Aires" }
hCountries += { 'Brasil' => "Brasilia" }
hCountries += { 'Chile' => "Santiago" }
hCountries += { 'Mexico' => "Mexico City" }
Hashs may add ( concatenate ) each other by extended “+” sign :
hFruits := { "fruits" => { "apple", "chery", "apricot" } }
hDays := { "days" => { "sunday", "monday" } }
hDoris := hFruits + hDays
Note: This “+” and “+=” operators depends xHB lib and needs to xHB lib and xHB.ch.
Typing :
<key> part of a hash may be any legal scalar type : C, D, L, N; and <value> part may be in addition scalar types, any complex type ( array or hash ).
Correction : This definition is wrong ! The correct is :
<key> entry key; can be of type: number, date, datetime, string, pointer.
Corrected at : 2015.12.08; thanks to Marek.
hDigits_2 := { 1 => “One”, 2 => “Two”, 3 => “Three”, 4 => “Four” }
hDigits_3 := { "1" => "One", "2" => "Two", "3" => "Three", "4" => "Four" }
hDigits_4 := { "1" => "One", 2 => "Two", 3 => "Three", "4" => "Four" }
hDigits_5 := { 1 => "One", 1 => "Two", 3 => "Three", 4 => "Four"
All of these examples are legal. As a result, a pair record of a hash may be:
– Numeric key, numeric value ( hDigits_1 )
– Numeric key, character value ( hDigits_2 )
– Character key, character value ( hDigits_3 )
– Mixed type key ( hDigits_4 )
Duplicate keys (as seen in hDigits_5) is permitted to assign, but not give a result such as double keyed values: LEN( hDigits_5 ) is 3, not 4; because first pair replaced by second due to has same key.
Consider a table-like data for customers records with two character fields: Customer ID and customer name:
| Cust_ID | Cust_Name |
| CC001 | Pierce Firth |
| CC002 | Stellan Taylor |
| CC003 | Chris Cherry |
| CC004 | Amanda Baranski |
We can build a hash with this data :
hCustomers := { "CC001" => "Pierce Firth",;
"CC002" => "Stellan Taylor",;
"CC003" => "Chris Cherry",;
"CC004" => "Amanda Baranski" }
and list it:
?
? "Listing a hash :"
?
h1Record := NIL
FOR EACH h1Record IN hCustomers
? cLMarj, h1Record:__ENUMKEY(), h1Record:__ENUMVALUE()
NEXT
Accessing a specific record is easy :
hCustomers[ "CC003" ] // Chris Cherry
*-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.
/*
Hash Basics
*/
#include "xhb.ch"
#define NTrim( n ) LTRIM( STR( n ) )
PROCEDURE Main()
SET DATE GERM
SET CENT ON
SET COLO TO "W/B"
cLMarj := SPACE( 3 )
CLS
hDigits_1 := { => } // Build an empty hash
hDigits_1[ 1 ] := 1
hDigits_1[ 2 ] := 2
hDigits_1[ 3 ] := 3
hDigits_1[ 4 ] := 4
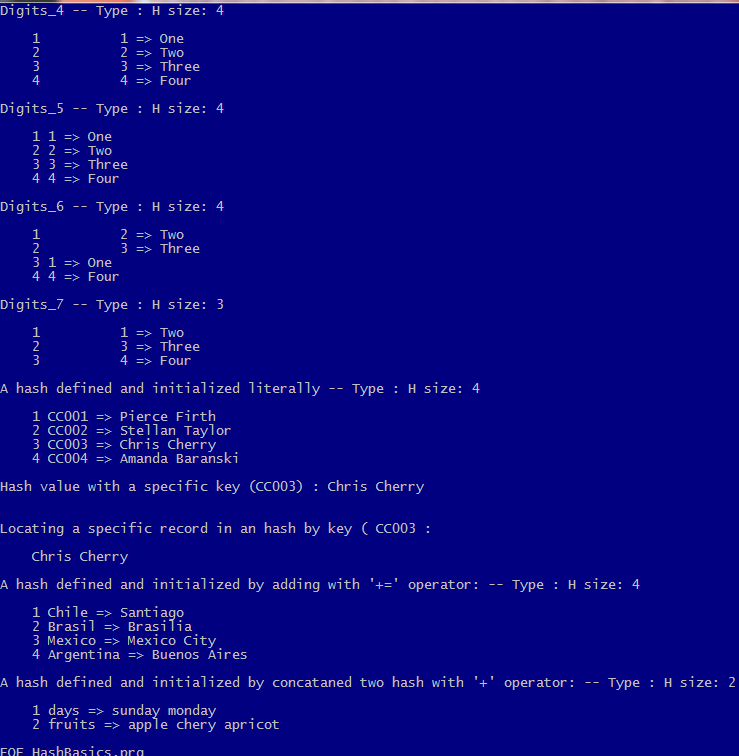
ListHash( hDigits_1, "Digits_1" )
hDigits_2 := HB_HASH( 1, 1, 2, 2, 3, 3, 4, 4 )
ListHash( hDigits_2, "Digits_2" )
hDigits_3 := { 1 => 1,;
2 => 2,;
3 => 3,;
4 => 4 }
ListHash( hDigits_3, "Digits_3" )
hDigits_4 := { 1 => "One",;
2 => "Two",;
3 => "Three",;
4 => "Four" }
ListHash( hDigits_4, "Digits_4" )
hDigits_5 := { "1" => "One",;
"2" => "Two",;
"3" => "Three",;
"4" => "Four" }
ListHash( hDigits_5, "Digits_5" )
hDigits_6 := { "1" => "One",;
2 => "Two",;
3 => "Three",;
"4" => "Four" }
ListHash( hDigits_6, "Digits_6" )
hDigits_7 := { 1 => "One",;
1 => "Two",; // This line replace to previous due to same key
3 => "Three",;
4 => "Four" }
ListHash( hDigits_7, "Digits_7" )
* WAIT "EOF digits"
hCustomers := { "CC001" => "Pierce Firth",;
"CC002" => "Stellan Taylor",;
"CC003" => "Chris Cherry",;
"CC004" => "Amanda Baranski" }
ListHash( hCustomers, "A hash defined and initialized literally" )
?
? "Hash value with a specific key (CC003) :", hCustomers[ "CC003" ] // Chris Cherry
?
cKey := "CC003"
?
? "Locating a specific record in an hash by key (", cKey, ":"
?
c1Data := hCustomers[ cKey ]
? cLMarj, c1Data
hCountries := { 'Argentina' => "Buenos Aires" }
hCountries += { 'Brasil' => "Brasilia" }
hCountries += { 'Chile' => "Santiago" }
hCountries += { 'Mexico' => "Mexico City" }
ListHash( hCountries, "A hash defined and initialized by adding with '+=' operator:" )
hFruits := { "fruits" => { "apple", "chery", "apricot" } }
hDays := { "days" => { "sunday", "monday" } }
hDoris := hFruits + hDays
ListHash( hDoris, "A hash defined and initialized by concataned two hash with '+' operator:" )
?
@ MAXROW(), 0
WAIT "EOF HashBasics.prg"
RETURN // HashBasics.Main()
*-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.
PROCEDURE ListHash( hHash, cComment )
LOCAL x1Pair := NIL
cComment := IF( HB_ISNIL( cComment ), '', cComment )
?
? cComment, "-- Type :", VALTYPE( hHash ), "size:", NTrim ( LEN( hHash ) )
?
FOR EACH x1Pair IN hHash
nIndex := x1Pair:__ENUMINDEX()
x1Key := x1Pair:__ENUMKEY()
x1Value := x1Pair:__ENUMVALUE()
? cLMarj, NTrim( nIndex )
* ?? '', VALTYPE( x1Pair )
?? '', x1Key, "=>"
* ?? '', VALTYPE( x1Key )
* ?? VALTYPE( x1Value )
IF HB_ISARRAY( x1Value )
AEVAL( x1Value, { | x1 | QQOUT( '', x1 ) } )
ELSE
?? '', x1Value
ENDIF
NEXT
RETURN // ListHash()
*-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.-._.

/*
ForEach.prg
In addition clasical FOR..NEXT loop, Harbour offers another FOR loop :
FOR EACH..NEXT.
Simplest syntax of this loop is :
FOR EACH <xValue> IN <xList>
...
NEXT
For arrays, this structure is equivalent to :
FOR <nIndex> := 1 TO LEN( <aArray> )
<xValue> := <aArray>[ nIndex ]
...
NEXT
Relations and rules for <xValue> and <xList> in FOR EACH loop :
If <xList> is ... <xValue> is ...
----------------- ----------------
<array> an element of <array>
<string> a single character in the <string>
<hash> <xValue> of <xKey> => <xValue> pair in the <hash>
Strings can be processed by indexing like arrays.
For string iteration, lib is xHB, so you need add
xHB lib calling in the your compile command:
hbmk2 -lxHB ForEach
and add your source prg file :
#include "xhb.ch"
*/
#include "xhb.ch"
PROCEDURE Main()
CLS
aFruits := { "appricot", "cherry", "melon", "pear", "grapes", "mulberry" }
c1Fruit := '' // Variable for iteration value must be exist
// before FOR ... statement
?
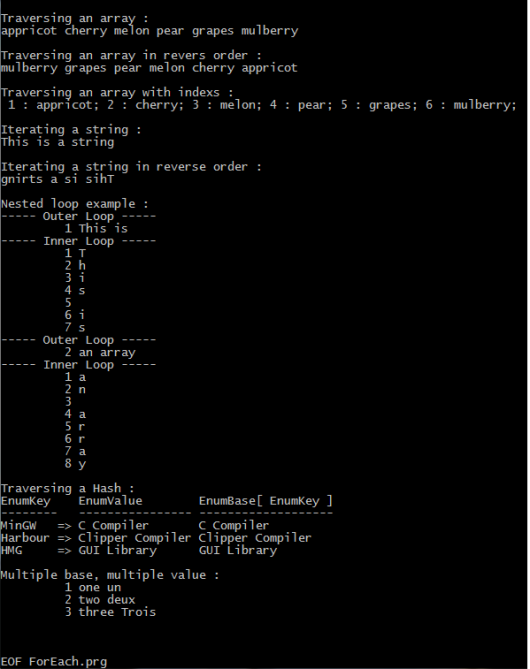
? "Traversing an array :"
?
FOR EACH c1Fruit IN aFruits
?? c1Fruit, ''
NEXT
/* Note that this loop is equivalent to :
?
FOR n1Fruit := 1 TO LEN( aFruits )
c1Fruit := aFruits[ n1Fruit ]
?? c1Fruit, ''
NEXT */
/* For a list in reverse order with classical FOR
?
FOR n1Fruit := LEN( aFruits ) TO 1 STEP -1
c1Fruit := aFruits[ n1Fruit ]
?? c1Fruit, ''
NEXT */
/* ... and with FOR EACH*/
?
? "Traversing an array in revers order :"
?
FOR EACH c1Fruit IN aFruits DESCEND
?? c1Fruit, ''
NEXT
/* Sometime we needs something like this :
?
FOR n1Fruit := 1 TO LEN( aFruits )
c1Fruit := aFruits[ n1Fruit ]
?? STR( n1Fruit, 2 ), ":", c1Fruit + ';'
NEXT */
/* FOR EACH loop allow us using some 'internal' functions;
but a 'special' way : */
?
? "Traversing an array with indexs :"
?
FOR EACH c1Fruit IN aFruits
?? STR( c1Fruit:__ENUMINDEX(), 2 ), ":", c1Fruit + ';'
NEXT
cString := "This is a string"
/* ... and a string example :
?
? "Iterating a string by FOR .. NEXT :"
?
FOR nIndex := 1 TO LEN( cString )
?? cString[ nIndex ]
NEXT */
c1Char := ''
?
? "Iterating a string :"
?
FOR EACH c1Char IN cString
?? c1Char
NEXT
?
? "Iterating a string in reverse order :"
?
FOR EACH c1Char IN cString DESCEND
?? c1Char
NEXT
?
? "Nested loop example :"
aArray := { "This is", "an array" }
c1String := ''
FOR EACH c1String IN aArray
? "----- Outer Loop -----"
? c1String:__ENUMINDEX(), c1String
? "----- Inner Loop -----"
FOR EACH c1Char IN c1String
? c1Char:__ENUMINDEX(), c1Char
NEXT
NEXT
?
? "Traversing a Hash : "
? "EnumKey EnumValue EnumBase[ EnumKey ]"
? "-------- ---------------- -------------------"
hSoftWare := { => }
HB_HKeepOrder( hSoftWare, .T. )
hSoftWare['MinGW ' ] := 'C Compiler '
hSoftWare['Harbour' ] := 'Clipper Compiler'
hSoftWare['HMG ' ] := 'GUI Library '
hProgram := NIL // { => }
FOR EACH hProgram IN hSoftWare
? hProgram:__ENUMKEY(), "=>", hProgram:__ENUMVALUE(),;
hProgram:__ENUMBASE()[hProgram:__ENUMKEY()] // Alternate syntax
NEXT
?
? "Multiple base, multiple value : "
aArrayNr := { 1, 2, 3 }
aArrayEn := { "one", "two", "three" }
aArrayFr := { "un", "deux", "Trois" }
cNumNr := 0
cNumEn := ''
cNumFr := ''
FOR EACH cNumNr, cNumEn, cNumFr IN aArrayNr, aArrayEn, aArrayFr
? cNumNr, cNumEn, cNumFr
NEXT
@ MAXROW(), 0
WAIT "EOF ForEach.prg"
RETURN // ForEach.Prg.Main()
/*
Operator overloading
Some operators overloaded by extending their functionalities.
"$" was an operator for "checking substring existence in a string"
For example :
? "A" $ "ABC" // Result: .T.
? "Z" $ "ABC" // Result: .F.
Now, this operator can be used for arrays and hashs too, not only strings.
See examples below.
"=>" was a preprocessor operator with meaning "translate to : ...".
Now, this operator can be used as a <key> - <value> separator in Hashs
for define and / or assign <key> - <value> to Hashs.
See examples below.
"[ ]" was Array element indicator (Special)
"{ }" was Literal array and code block delimiters (Special)
Now, this indicators can be used for hashs too.
See examples below.
"+=" is self-increment operator that can be used both numeric
and string values.
Such as :
cTest := "This"
cTest += " is"
? cTest // This is
nTest := 3
nTest += 10
? nTest // 13
Now, this operator can be used for adding elements to an existing hash;
( but no for arrays ! ).
Note : Extended functionalities of $ and += operators depends xHB lib.
So need this usages to xHB lib and xHB.ch.
See examples below.
*/
#include "xhb.ch"
PROCEDURE Main()
CLS
aFruits := { "apple", "appricot", "cherry", "melon", "pear", "mulberry" }
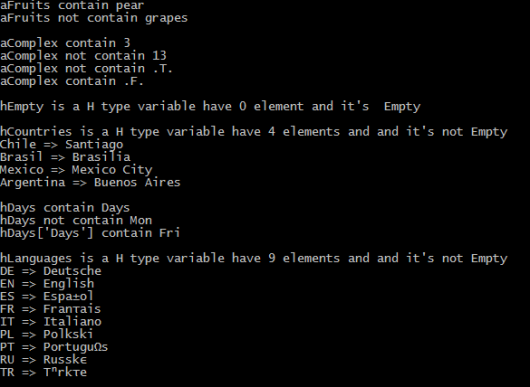
? "aFruits", IF( "pear" $ aFruits, '', 'not ' ) + "contain pear"
? "aFruits", IF( "grapes" $ aFruits, '', 'not ' ) +"contain grapes"
aComplex := ARRAY( 10 )
AEVAL( aComplex, { | x1, i1 | aComplex[ i1 ] := i1 } )
aComplex[ 5 ] := DATE()
aComplex[ 7 ] := .F.
?
? "aComplex", IF( 3 $ aComplex, '', 'not ' ) + "contain 3"
? "aComplex", IF( 13 $ aComplex, '', 'not ' ) + "contain 13"
? "aComplex", IF( .T. $ aComplex, '', 'not ' ) + "contain .T."
? "aComplex", IF( .F. $ aComplex, '', 'not ' ) + "contain .F."
hEmpty := { => }
?
? "hEmpty is a", VALTYPE( hEmpty ), "type variable have",;
STR( LEN( hEmpty ), 1 ), "element and it's",;
IF( EMPTY( hEmpty ), '', 'not' ), "Empty"
hCountries := { 'Argentina' => "Buenos Aires" }
hCountries += { 'Brasil' => "Brasilia" }
hCountries += { 'Chile' => "Santiago" }
hCountries += { 'Mexico' => "Mexico City" }
?
? "hCountries is a", VALTYPE( hCountries ), "type variable have",;
STR( LEN( hCountries ), 1 ), "elements and and it's",;
IF( EMPTY( hCountries ), '', 'not' ), "Empty"
cCountry := NIL
FOR EACH cCountry IN hCountries
? cCountry:__ENUMKEY(), "=>", cCountry:__ENUMVALUE()
NEXT
hDays := { 'Days' => { "Mon", "Tue", "Wed", "Thu", "Fri", "Sat", "Sun" } }
?
? "hDays", IF( 'Days' $ hDays, '', 'not ' ) + "contain Days"
? "hDays", IF( "Mon" $ hDays, '', 'not ' ) + "contain Mon"
? "hDays['Days']", IF( "Fri" $ hDays["Days"], '', 'not ' ) + "contain Fri"
hLanguages := { "EN" => "English" } +;
{ "DE" => "Deutsche" } +;
{ "ES" => "Español" } +;
{ "FR" => "Français" } +;
{ "IT" => "Italiano" } +;
{ "PL" => "Polkski" } +;
{ "PT" => "Português" } +;
{ "RU" => "Russkî" } +;
{ "TR" => "Türkçe" }
?
? "hLanguages is a", VALTYPE( hLanguages ), "type variable have",;
STR( LEN( hLanguages ), 1 ), "elements and and it's",;
IF( EMPTY( hLanguages ), '', 'not' ), "Empty"
cLanguage := NIL
FOR EACH cLanguage IN hLanguages
? cLanguage:__ENUMKEY(), "=>", cLanguage:__ENUMVALUE()
NEXT
@ MAXROW(), 0
WAIT "EOF OprOLoad.prg"
RETURN // OprOLoad.Prg.Main()