/*
From Harbour changelog (at 2007-04-04 10:35 UTC+0200 By Przemyslaw Czerpak )
Added set of functions to manipulate string tokens:
HB_TOKENCOUNT( <cString>, [ <cDelim> ], [ <lSkipStrings> ],
[ <lDoubleQuoteOnly> ] ) -> <nTokens>
HB_TOKENGET( <cString>, <nToken>, [ <cDelim> ], [ <lSkipStrings> ],
[ <lDoubleQuoteOnly> ] ) -> <cToken>
HB_TOKENPTR( <cString>, @<nSkip>, [ <cDelim> ], [ <lSkipStrings> ],
[ <lDoubleQuoteOnly> ] ) -> <cToken>
HB_ATOKENS( <cString>, [ <cDelim> ], [ <lSkipStrings> ],
[ <lDoubleQuoteOnly> ] ) -> <aTokens>
All these functions use the same method of tokenization. They can
accept as delimiters string longer then one character. By default
they are using " " as delimiter. " " delimiter has special mening
Unlike other delimiters repeted ' ' characters does not create empty
tokens, f.e.:
HB_ATOKENS( " 1 2 3 " ) returns array:
{ "1", "2", "3" }
Any other delimiters are restrictly counted, f.e.:
HB_ATOKENS( ",,1,,2,") returns array:
{ "", "", "1", "", "2", "" }
And a strong suggession made at 2009-12-09 21:25 UTC+0100 ( By Przemyslaw Czerpak )
I strongly suggest to use hb_aTokens() and hb_token*() functions.
They have more options and for really large data many times
(even hundreds times) faster.
*/
#define CRLF HB_OsNewLine()
PROCEDURE Main()
LOCAL cTextFName := "Shakespeare.txt",;
c1Line
SET COLO TO "W/B"
SetMode( 40, 120 )
CLS
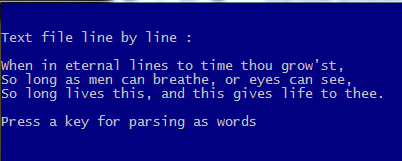
HB_MEMOWRIT( cTextFName,;
"When in eternal lines to time thou grow'st," + CRLF + ;
"So long as men can breathe, or eyes can see," + CRLF + ;
"So long lives this, and this gives life to thee." )
aLines := HB_ATOKENS( MEMOREAD( cTextFName ), CRLF )
?
? "Text file line by line :"
?
AEVAL( aLines, { | c1Line | QOUT( c1Line ) } )
?
WAIT "Press a key for parsing as words"
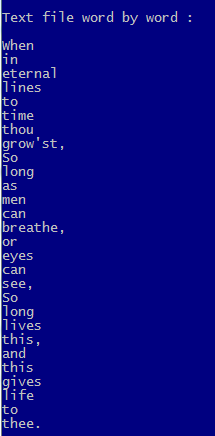
CLS
?
? "Text file word by word :"
?
FOR EACH c1Line IN aLines
a1Line := HB_ATOKENS( c1Line )
AEVAL( a1Line, { | c1Word | QOUT( c1Word ) } )
NEXT
?
WAIT "Press a key for parsing directly as words"
CLS
?
? "Text file directly word by word :"
?
aWords := HB_ATOKENS( MEMOREAD( cTextFName ) )
AEVAL( aWords, { | c1Word | QOUT( c1Word ) } )
?
@ MAXROW(), 0
WAIT "EOF TP_Token.prg"
RETURN // TP_Token.Main()